
הצגת HTML באמצעות JavaScript שונה מהצגת HTML שנשלח על ידי השרת, וזה יכול להשפיע על הביצועים. במדריך הזה מוסבר מה ההבדל בין שני המושגים, ומה אפשר לעשות כדי לשמור על ביצועי העיבוד של האתר – במיוחד כשמדובר באינטראקציות.

ניתוח והצגה של HTML הם דברים שדפדפנים עושים טוב מאוד כברירת מחדל באתרים שמשתמשים בלוגיקת הניווט המובנית של הדפדפן – לפעמים קוראים לזה 'טעינות דפים רגילות' או 'ניווטים קשים'. אתרים כאלה נקראים לפעמים אפליקציות מרובות דפים (MPA).
עם זאת, מפתחים יכולים לעקוף את ברירות המחדל של הדפדפן כדי להתאים אותן לצרכים של האפליקציה שלהם. זה נכון במיוחד לגבי אתרים שמשתמשים בתבנית של אפליקציית דף יחיד (SPA), שיוצרת באופן דינמי חלקים גדולים של ה-HTML/DOM בלקוח באמצעות JavaScript. השם של תבנית העיצוב הזו הוא עיבוד בצד הלקוח, והיא יכולה להשפיע על מהירות התגובה לאינטראקציה באתר (INP) אם העבודה שנדרשת היא מוגזמת.
המדריך הזה יעזור לכם להבין את ההבדל בין שימוש ב-HTML שנשלח מהשרת לדפדפן לבין יצירת HTML בצד הלקוח באמצעות JavaScript, ואיך האפשרות השנייה עלולה לגרום לזמן אחזור גבוה של אינטראקציה ברגעים קריטיים.
איך הדפדפן מעבד HTML שסופק על ידי השרת
דפוסי הניווט שמשמשים בטעינות דפים רגילות כוללים קבלת HTML מהשרת בכל ניווט. אם מזינים כתובת URL בסרגל הכתובות של הדפדפן או לוחצים על קישור ב-MPA, מתרחשת סדרת האירועים הבאה:
- הדפדפן שולח בקשת ניווט לכתובת ה-URL שצוינה.
- השרת מגיב עם HTML במנות.
השלב האחרון הוא הכי חשוב. זה גם אחד מהשיפורים הכי בסיסיים בביצועים בהעברה בין השרת לדפדפן, והוא נקרא סטרימינג. אם השרת יכול להתחיל לשלוח HTML בהקדם האפשרי, והדפדפן לא מחכה להגעת התגובה כולה, הדפדפן יכול לעבד את ה-HTML בחלקים כשהוא מגיע.
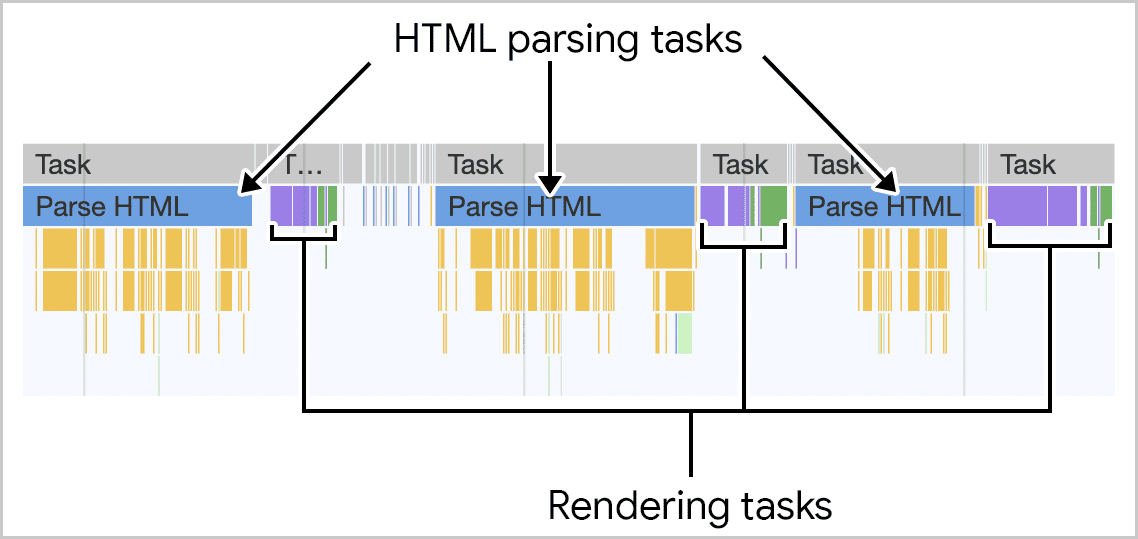
כמו רוב הפעולות שמתבצעות בדפדפן, ניתוח ה-HTML מתבצע במסגרת משימות. כש-HTML מועבר בסטרימינג מהשרת לדפדפן, הדפדפן מבצע אופטימיזציה של הניתוח של ה-HTML הזה על ידי ניתוח קצת בכל פעם, כשחלקים מהסטרימינג מגיעים במנות. התוצאה היא שהדפדפן מפנה את השרשור הראשי מעת לעת אחרי עיבוד כל נתח, וכך נמנעות משימות ארוכות. המשמעות היא שאפשר לבצע עבודות אחרות בזמן שה-HTML עובר ניתוח, כולל עבודות עיבוד מצטברות שנדרשות כדי להציג דף למשתמש, וגם עיבוד של אינטראקציות של משתמשים שעשויות להתרחש במהלך תקופת ההפעלה הקריטית של הדף. הגישה הזו משפרת את הציון של מהירות התגובה לאינטראקציה באתר (INP) בדף.
מה אפשר ללמוד מזה? כשמבצעים סטרימינג של HTML מהשרת, מקבלים ניתוח הדרגתי ועיבוד של HTML והעברה אוטומטית לשרשור הראשי בחינם. זה לא קורה כשמשתמשים בעיבוד בצד הלקוח.
איך הדפדפן מעבד HTML שסופק על ידי JavaScript
כל בקשת ניווט לדף מחייבת שהשרת יספק כמות מסוימת של HTML, אבל יש אתרים שמשתמשים בתבנית SPA. הגישה הזו כוללת בדרך כלל מטען ייעודי מינימלי של HTML שהשרת מספק, אבל אז הלקוח יאכלס את אזור התוכן הראשי של הדף באמצעות HTML שנבנה מנתונים שנשלפו מהשרת. מעברים בין דפים שמתבצעים לאחר מכן – שלפעמים נקראים במקרה הזה 'מעברים רכים בין דפים' – מטופלים באופן מלא על ידי JavaScript כדי לאכלס את הדף ב-HTML חדש.
יכול להיות שיהיה רינדור בצד הלקוח גם באתרים שהם לא SPA, במקרים מוגבלים יותר שבהם קוד HTML מתווסף באופן דינמי ל-DOM באמצעות JavaScript.
יש כמה דרכים נפוצות ליצור HTML או להוסיף ל-DOM באמצעות JavaScript:
- המאפיין
innerHTMLמאפשר להגדיר את התוכן ברכיב קיים באמצעות מחרוזת, שהדפדפן מנתח ל-DOM. - השיטה
document.createElementמאפשרת ליצור רכיבים חדשים שיוספו ל-DOM בלי להשתמש בניתוח HTML של הדפדפן. - השיטה
document.writeמאפשרת לכתוב קוד HTML למסמך (והדפדפן מנתח אותו, בדיוק כמו בגישה מספר 1). עם זאת, לא מומלץ להשתמש ב-document.writeמכמה סיבות.

ההשלכות של יצירת HTML/DOM באמצעות JavaScript בצד הלקוח יכולות להיות משמעותיות:
- בניגוד ל-HTML שמוזרם על ידי השרת בתגובה לבקשת ניווט, משימות JavaScript בלקוח לא מחולקות אוטומטית לחלקים, ולכן יכול להיות שיהיו משימות ארוכות שחוסמות את השרשור הראשי. המשמעות היא שערך ה-INP של הדף יכול להיפגע אם יוצרים יותר מדי HTML או DOM בו-זמנית בצד הלקוח.
- אם קוד ה-HTML נוצר בלקוח במהלך ההפעלה, הדפדפן לא יזהה את המשאבים שמפנים אליהם בסורק הטעינה מראש. הדבר הזה ישפיע בוודאות באופן שלילי על המהירות שבה נטען רכיב התוכן הכי גדול (LCP) בדף. למרות שזו לא בעיה בביצועים בזמן ריצה (אלא בעיה של עיכוב ברשת באחזור משאבים חשובים), לא כדאי שערך ה-LCP של האתר שלכם יושפע ממעקף של האופטימיזציה הבסיסית הזו של ביצועי הדפדפן.
מה אפשר לעשות כדי לצמצם את ההשפעה של רינדור בצד הלקוח על הביצועים
אם האתר שלכם מסתמך במידה רבה על עיבוד בצד הלקוח, וזיהיתם ערכי INP נמוכים בנתוני השדה, יכול להיות שאתם תוהים אם יש קשר בין עיבוד בצד הלקוח לבעיה. לדוגמה, אם האתר שלכם הוא SPA, נתוני השדה עשויים לחשוף אינטראקציות שדורשות עבודת רינדור משמעותית.
לא משנה מה הסיבה, הנה כמה סיבות אפשריות שכדאי לבדוק כדי לפתור את הבעיה.
מספקים כמה שיותר קוד HTML מהשרת
כמו שציינתי קודם, הדפדפן מטפל ב-HTML מהשרת בצורה יעילה מאוד כברירת מחדל. הוא יפצל את הניתוח והעיבוד של ה-HTML באופן שימנע משימות ארוכות, וימטב את משך הזמן הכולל של ה-thread הראשי. התוצאה היא זמן חסימה כולל (TBT) נמוך יותר, ויש מתאם חזק בין TBT לבין INP.
יכול להיות שאתם מסתמכים על מסגרת frontend כדי לבנות את האתר שלכם. אם כן, כדאי לוודא שאתם מבצעים רינדור של רכיב HTML בשרת. כך תצטרכו לבצע פחות עיבוד בצד הלקוח בהתחלה באתר, והתוצאה תהיה חוויה טובה יותר.
- ב-React, כדאי להשתמש ב-Server DOM API כדי לעבד HTML בשרת. אבל חשוב לדעת: השיטה המסורתית של רינדור בצד השרת משתמשת בגישה סינכרונית, שיכולה להוביל לזמן ארוך יותר עד לבייט הראשון (TTFB), וגם למדדים הבאים כמו הצגת תוכן ראשוני (FCP) ו-LCP. במקרים שבהם הדבר אפשרי, כדאי להשתמש בממשקי ה-API לסטרימינג של Node.js או סביבות זמן ריצה אחרות של JavaScript, כדי שהשרת יוכל להתחיל להזרים HTML לדפדפן בהקדם האפשרי. Next.js – מסגרת מבוססת-React – מספקת כברירת מחדל הרבה שיטות מומלצות. בנוסף להצגת HTML אוטומטית בשרת, אפשר גם ליצור HTML סטטי לדפים שלא משתנים על סמך הקשר של המשתמש (למשל, אימות).
- ב-Vue, הרינדור מצד הלקוח מתבצע כברירת מחדל. עם זאת, כמו React, Vue יכולה גם לעבד את ה-HTML של הרכיב בשרת. אפשר לנצל את ממשקי ה-API האלה בצד השרת כשהדבר אפשרי, או לשקול הפשטה ברמה גבוהה יותר בפרויקט Vue כדי להקל על יישום השיטות המומלצות.
- Svelte מעבד HTML בשרת כברירת מחדל – אבל אם קוד הרכיב שלכם צריך גישה למרחבי שמות בלעדיים לדפדפן (למשל
window), יכול להיות שלא תוכלו לעבד את ה-HTML של הרכיב הזה בשרת. כדאי לבחון גישות חלופיות בכל מקום שאפשר, כדי לא לגרום לרינדור מיותר בצד הלקוח. SvelteKit – הוא ל-Svelte כמו ש-Next.js הוא ל-React – מטמיע כמה שיותר שיטות מומלצות בפרויקטים של Svelte, כדי שתוכלו להימנע מטעויות אפשריות בפרויקטים שמשתמשים ב-Svelte בלבד.
הגבלת מספר צומתי ה-DOM שנוצרים בצד הלקוח
כשה-DOM גדול, בדרך כלל נדרש יותר עיבוד כדי לעבד אותו. לא משנה אם האתר שלכם הוא SPA מלא או שהוא מוסיף צמתים חדשים ל-DOM קיים כתוצאה מאינטראקציה עם MPA, מומלץ לשמור על גודל ה-DOM כמה שיותר קטן. כך תוכלו להפחית את העבודה שנדרשת במהלך רינדור בצד הלקוח כדי להציג את ה-HTML, ולקוות שהערך של INP באתר יישאר נמוך.
כדאי לשקול ארכיטקטורה של קובץ שירות (service worker) לסטרימינג
זו טכניקה מתקדמת, שלא תמיד פועלת בקלות בכל תרחיש שימוש, אבל היא יכולה להפוך את ה-MPA לאתר שמרגיש כאילו הוא נטען באופן מיידי כשמשתמשים עוברים מדף אחד לדף אחר. אתם יכולים להשתמש בקובץ שירות כדי לשמור במטמון מראש את החלקים הסטטיים של האתר ב-CacheStorage, ובמקביל להשתמש ב-ReadableStream API כדי לאחזר מהשרת את שאר קוד ה-HTML של הדף.
כשמשתמשים בטכניקה הזו בצורה נכונה, לא נוצר HTML בצד הלקוח, אבל הטעינה המיידית של חלקי תוכן מהמטמון יוצרת את הרושם שהאתר נטען במהירות. אתרים שמשתמשים בגישה הזו יכולים להרגיש כמעט כמו SPA, אבל בלי החסרונות של עיבוד בצד הלקוח. היא גם מצמצמת את כמות ה-HTML שאתם מבקשים מהשרת.
בקיצור, ארכיטקטורה של Service Worker להזרמת נתונים לא מחליפה את לוגיקת הניווט המובנית של הדפדפן, אלא מוסיפה עליה. למידע נוסף על איך עושים את זה באמצעות Workbox, אפשר לקרוא את המאמר Faster multipage applications with streams.
סיכום
האופן שבו האתר מקבל ומעבד HTML משפיע על הביצועים. כשמסתמכים על השרת כדי לשלוח את כל קוד ה-HTML שנדרש לאתר (או את רובו), מקבלים הרבה יתרונות בחינם: ניתוח והצגה מצטברים, והעברה אוטומטית ל-main thread כדי להימנע ממשימות ארוכות.
עיבוד HTML בצד הלקוח עלול לגרום לבעיות בביצועים, שאפשר למנוע אותן ברוב המקרים. עם זאת, בגלל הדרישות של כל אתר בנפרד, אי אפשר להימנע לחלוטין מהצגת מודעות כאלה בכל המקרים. כדי לצמצם את הסיכון למשימות ארוכות שעלולות לנבוע מרינדור מוגזם בצד הלקוח, חשוב לשלוח מהשרת כמה שיותר קוד HTML של האתר, לשמור על גודל ה-DOM קטן ככל האפשר עבור קוד HTML שחייב לעבור רינדור בצד הלקוח, ולשקול ארכיטקטורות חלופיות כדי להאיץ את המסירה של קוד HTML ללקוח, תוך ניצול הניתוח והרינדור המצטברים שהדפדפן מספק לקוד HTML שנטען מהשרת.
אם תצליחו לצמצם ככל האפשר את העיבוד בצד הלקוח באתר, תשפרו לא רק את מדד ה-INP של האתר, אלא גם מדדים אחרים כמו LCP, TBT ואולי אפילו TTFB במקרים מסוימים.
תמונה ראשית (Hero) מ-Unsplash, מאת Maik Jonietz.