
Scopri come ottimizzare la metrica Time to First Byte.


Il Time to First Byte (TTFB) è una metrica fondamentale delle prestazioni web che precede tutte le altre metriche significative dell'esperienza utente, come First Contentful Paint (FCP) e Largest Contentful Paint (LCP). Ciò significa che i valori TTFB elevati aggiungono tempo alle metriche che seguono.
Ti consigliamo di fare in modo che il server risponda alle richieste di navigazione abbastanza rapidamente da consentire al 75° percentile degli utenti di sperimentare un FCP entro la soglia "buona". Come indicazione di massima, la maggior parte dei siti dovrebbe puntare a un TTFB di 0,8 secondi o meno.

Come misurare il TTFB
Prima di poter ottimizzare il TTFB, devi osservare in che modo influisce sugli utenti del tuo sito web. Devi fare affidamento sui dati di campo come fonte principale per osservare il TTFB influenzato dai reindirizzamenti, mentre gli strumenti basati su laboratorio vengono spesso misurati utilizzando l'URL finale, quindi non tengono conto di questo ritardo aggiuntivo.
PageSpeed Insights è un modo per ottenere informazioni sul campo e di laboratorio per i siti web pubblici disponibili nel Report sull'esperienza utente di Chrome.
Il TTFB per gli utenti reali viene visualizzato nella sezione superiore Scopri com'è l'esperienza dei tuoi utenti reali:
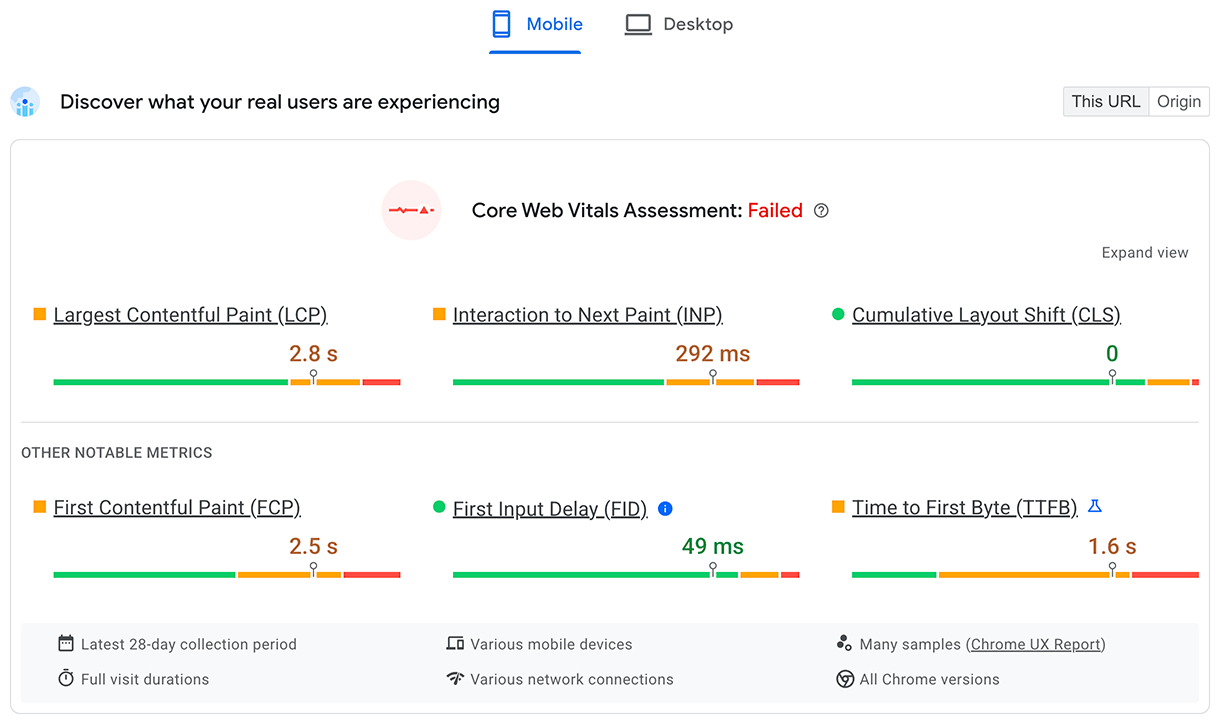
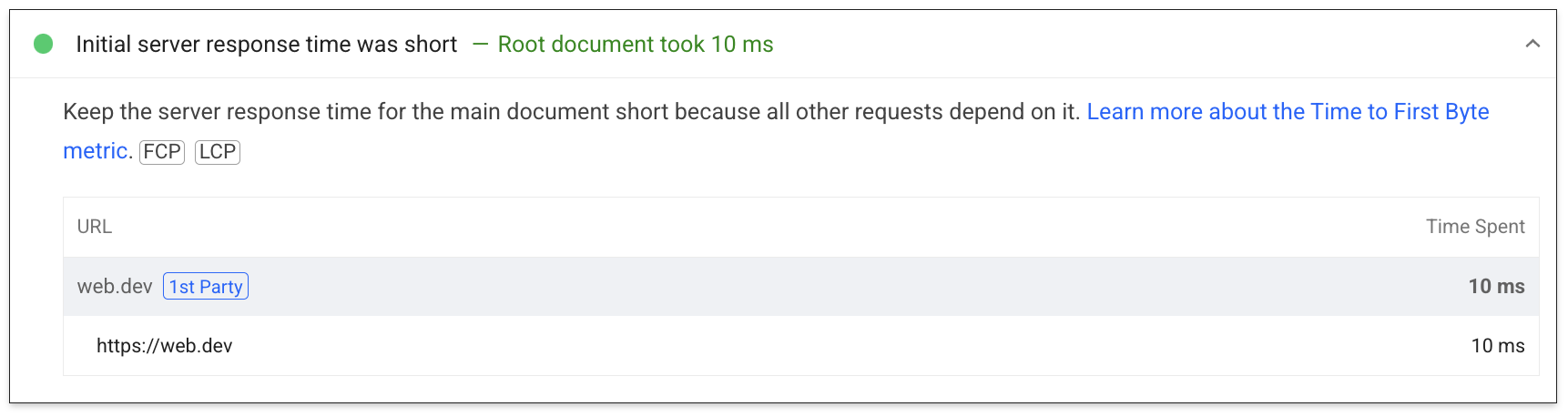
Per i dati di laboratorio, un sottoinsieme di TTFB viene mostrato nel controllo del tempo di risposta del server:
Per scoprire altri modi per misurare il TTFB sia sul campo che in laboratorio, consulta la pagina della metrica TTFB.
Comprendere le differenze tra TTFB sul campo e in laboratorio
Il TTFB di laboratorio e sul campo può variare per diversi motivi e, quando ciò accade, è importante capire perché per poter utilizzare in modo efficace i dati di laboratorio per migliorare le esperienze utente.
Quando il TTFB del lab è molto più grande del TTFB sul campo, significa che l'ambiente lab è più vincolato rispetto alle esperienze utente tipiche. Non si tratta necessariamente di un problema, in quanto i risultati e i consigli del lab saranno probabilmente ancora validi, ma potrebbero esagerare l'impatto e il miglioramento.
Quando il campo TTFB è molto più grande del TTFB di laboratorio, ciò indica problemi non evidenti durante l'esecuzione in laboratorio, come l'utilizzo della memorizzazione nella cache lato server, reindirizzamenti o differenze di rete. In questo caso, i risultati e i consigli del laboratorio potrebbero essere meno utili, in quanto non tengono conto di uno dei problemi principali.
Per verificare se la memorizzazione nella cache lato server influisce sul TTFB di Lab, prova a testare pagine meno comuni o a utilizzare parametri URL diversi per ottenere contenuti non memorizzati nella cache e verificare se il TTFB è più in linea con il TTFB sul campo. Può anche essere utile avere la possibilità di bypassare la memorizzazione nella cache lato server con un determinato parametro URL. Consulta la sezione sui contenuti memorizzati nella cache.
Per i reindirizzamenti e le differenze di rete, l'analisi di come e da dove proviene il traffico verso il nostro sito può essere utile per diagnosticare se si tratta di potenziali problemi.
Esegui il debug di TTFB elevato sul campo con Server-Timing
L'intestazione della risposta Server-Timing può essere utilizzata nel backend dell'applicazione per misurare i diversi processi di backend che potrebbero contribuire a una latenza elevata. La struttura del valore dell'intestazione è flessibile e accetta, come minimo, un handle che definisci. I valori facoltativi includono un valore di durata (tramite dur), nonché una descrizione facoltativa leggibile (tramite desc).
Serving-Timing può essere utilizzato per misurare molti processi di backend delle applicazioni, ma ce ne sono alcuni a cui potresti voler prestare particolare attenzione:
- Query database
- Tempo di rendering lato server, se applicabile
- Ricerca disco
- Successi o fallimenti della cache del server perimetrale (se utilizzi una CDN)
Tutte le parti di una voce Server-Timing sono separate da due punti e più voci possono essere separate da una virgola:
// Two metrics with descriptions and values
Server-Timing: db;desc="Database";dur=121.3, ssr;desc="Server-side Rendering";dur=212.2
L'intestazione può essere impostata utilizzando la lingua che preferisci per il backend dell'applicazione. In PHP, ad esempio, puoi impostare l'intestazione nel seguente modo:
<?php
// Get a high-resolution timestamp before
// the database query is performed:
$dbReadStartTime = hrtime(true);
// Perform a database query and get results...
// ...
// Get a high-resolution timestamp after
// the database query is performed:
$dbReadEndTime = hrtime(true);
// Get the total time, converting nanoseconds to
// milliseconds (or whatever granularity you need):
$dbReadTotalTime = ($dbReadEndTime - $dbReadStartTime) / 1e+6;
// Set the Server-Timing header:
header('Server-Timing: db;desc="Database";dur=' . $dbReadTotalTime);
?>
Quando questa intestazione è impostata, vengono visualizzate informazioni che puoi utilizzare sia nel lab sia sul campo.
Nel campo, qualsiasi pagina con un'intestazione di risposta Server-Timing impostata compilerà la proprietà serverTiming nell'API Navigation Timing:
// Get the serverTiming entry for the first navigation request:
performance.getEntries('navigation')[0].serverTiming.forEach(entry => {
// Log the server timing data:
console.log(entry.name, entry.description, entry.duration);
});
Nel lab, i dati dell'intestazione della risposta Server-Timing verranno visualizzati nel riquadro dei tempi della scheda Rete in Chrome DevTools:

Intestazioni di risposta Server-Timing visualizzate nella scheda Rete di Chrome DevTools. In questo caso, Server-Timing viene utilizzato per misurare se una richiesta di una risorsa ha raggiunto la cache della CDN e quanto tempo impiega la richiesta per raggiungere l'edge server della CDN e poi l'origine.
Una volta stabilito che hai un TTFB problematico analizzando i dati disponibili, puoi passare alla risoluzione del problema.
Modi per ottimizzare il TTFB
L'aspetto più difficile dell'ottimizzazione del TTFB è che, mentre lo stack frontend del web sarà sempre HTML, CSS e JavaScript, gli stack backend possono variare in modo significativo. Esistono numerosi stack di backend e prodotti di database, ognuno con le proprie tecniche di ottimizzazione. Pertanto, questa guida si concentrerà su ciò che si applica alla maggior parte delle architetture, anziché concentrarsi esclusivamente sulle indicazioni specifiche dello stack.
Indicazioni specifiche per la piattaforma
La piattaforma che utilizzi per il tuo sito web può influire notevolmente sul TTFB. Ad esempio, le prestazioni di WordPress sono influenzate dal numero e dalla qualità dei plug-in o dai temi utilizzati. Anche altre piattaforme sono interessate in modo simile quando vengono personalizzate. Per consigli specifici per i fornitori, consulta la documentazione della tua piattaforma per integrare i suggerimenti più generali sulle prestazioni riportati in questo post. L'audit Lighthouse per la riduzione dei tempi di risposta del server include anche alcune indicazioni specifiche per lo stack limitate.
Hosting, hosting, hosting
Prima ancora di prendere in considerazione altri approcci di ottimizzazione, l'hosting dovrebbe essere la prima cosa da considerare. Non possiamo fornire indicazioni specifiche, ma una regola generale è assicurarsi che l'host del tuo sito web sia in grado di gestire il traffico che invii.
L'hosting condiviso è generalmente più lento. Se gestisci un piccolo sito web personale che serve principalmente file statici, probabilmente non ci sono problemi e alcune delle tecniche di ottimizzazione che seguono ti aiuteranno a ridurre il TTFB il più possibile.
Tuttavia, se esegui un'applicazione più grande con molti utenti che prevede la personalizzazione, l'interrogazione di database e altre operazioni lato server intensive, la scelta dell'hosting diventa fondamentale per ridurre il TTFB sul campo.
Quando scegli un provider di hosting, ecco alcuni aspetti da tenere presente:
- Quanta memoria è allocata all'istanza dell'applicazione? Se la tua applicazione non dispone di memoria sufficiente, avrà difficoltà a caricare le pagine il più rapidamente possibile.
- Il tuo provider di hosting mantiene aggiornato lo stack di backend? Man mano che vengono rilasciate nuove versioni di linguaggi di backend delle applicazioni, implementazioni HTTP e software di database, le prestazioni di questi software miglioreranno nel tempo. È fondamentale collaborare con un provider di hosting che dia la priorità a questo tipo di manutenzione cruciale.
- Se hai requisiti dell'applicazione molto specifici e vuoi il livello di accesso più basso ai file di configurazione del server, chiedi se è opportuno personalizzare il backend della tua istanza dell'applicazione.
Esistono molti provider di hosting che si occupano di queste cose per te, ma se inizi a osservare valori TTFB elevati anche nei provider di hosting dedicati, potrebbe essere un segnale che devi rivalutare le funzionalità del tuo attuale provider di hosting per offrire la migliore esperienza utente possibile.
Utilizzare una rete CDN (Content Delivery Network)
L'argomento Utilizzo della CDN è molto comune, ma per un buon motivo: potresti avere un backend dell'applicazione molto ben ottimizzato, ma gli utenti che si trovano lontano dal server di origine potrebbero comunque riscontrare un TTFB elevato sul campo.
Le CDN risolvono il problema della vicinanza degli utenti al server di origine utilizzando una rete distribuita di server che memorizzano nella cache le risorse su server fisicamente più vicini agli utenti. Questi server sono chiamati server edge.
I fornitori di CDN possono anche offrire vantaggi oltre ai server perimetrali:
- I provider CDN di solito offrono tempi di risoluzione DNS estremamente rapidi.
- Una CDN probabilmente pubblicherà i tuoi contenuti dai server edge utilizzando protocolli moderni come HTTP/2 o HTTP/3.
- In particolare, HTTP/3 risolve il problema di blocco head-of-line presente in TCP (su cui si basa HTTP/2) utilizzando il protocollo UDP.
- È probabile che una CDN fornisca anche versioni moderne di TLS, il che riduce la latenza coinvolta nel tempo di negoziazione TLS. In particolare, TLS 1.3 è progettato per mantenere la negoziazione TLS il più breve possibile.
- Alcuni provider CDN forniscono una funzionalità spesso chiamata "edge worker", che utilizza un'API simile a quella dell'API Service Worker per intercettare le richieste, gestire programmaticamente le risposte nelle cache edge o riscrivere completamente le risposte.
- I provider CDN sono molto bravi a eseguire l'ottimizzazione per la compressione. La compressione è difficile da eseguire in autonomia e in alcuni casi può comportare tempi di risposta più lenti con il markup generato dinamicamente, che deve essere compresso al volo.
- I provider CDN memorizzano automaticamente nella cache anche le risposte compresse per le risorse statiche, ottenendo il miglior mix di rapporto di compressione e tempo di risposta.
L'adozione di una CDN comporta un impegno variabile, da banale a significativo, ma dovrebbe essere una priorità assoluta per ottimizzare il TTFB se il tuo sito web non ne utilizza già una.
Utilizza i contenuti memorizzati nella cache, se possibile
Le CDN consentono di memorizzare nella cache i contenuti sui server perimetrali fisicamente più vicini ai visitatori, a condizione che i contenuti siano configurati con le intestazioni HTTP Cache-Control appropriate. Sebbene non sia appropriato per i contenuti personalizzati, richiedere un viaggio di ritorno all'origine può annullare gran parte del valore di una CDN.
Per i siti che aggiornano spesso i contenuti, anche un breve periodo di memorizzazione nella cache può comportare un notevole miglioramento delle prestazioni per i siti con traffico elevato, poiché solo il primo visitatore durante questo periodo subisce la latenza completa al server di origine, mentre tutti gli altri visitatori possono riutilizzare la risorsa memorizzata nella cache dal server edge. Alcune CDN consentono l'invalidazione della cache al momento del rilascio del sito, offrendo il meglio di entrambi i mondi: tempi di memorizzazione nella cache lunghi, ma aggiornamenti istantanei quando necessario.
Anche se la memorizzazione nella cache è configurata correttamente, può essere ignorata tramite l'utilizzo di parametri della stringa di query unici per la misurazione di Analytics. Questi contenuti potrebbero sembrare diversi per la CDN nonostante siano gli stessi, pertanto la versione memorizzata nella cache non verrà utilizzata.
Anche i contenuti meno recenti o meno visitati potrebbero non essere memorizzati nella cache, il che può comportare valori TTFB più elevati su alcune pagine rispetto ad altre. L'aumento dei tempi di memorizzazione nella cache può ridurre l'impatto di questo problema, ma tieni presente che con l'aumento dei tempi di memorizzazione nella cache aumenta la possibilità di pubblicare contenuti potenzialmente obsoleti.
L'impatto dei contenuti memorizzati nella cache non riguarda solo chi utilizza le CDN. L'infrastruttura del server potrebbe dover generare contenuti da costose ricerche nel database quando i contenuti memorizzati nella cache non possono essere riutilizzati. I dati a cui si accede più frequentemente o le pagine prememorizzate nella cache spesso hanno un rendimento migliore.
Evita i reindirizzamenti tra più pagine
Un fattore comune che contribuisce a un TTFB elevato sono i reindirizzamenti. I reindirizzamenti si verificano quando una richiesta di navigazione per un documento riceve una risposta che informa il browser che la risorsa esiste in un'altra posizione. Un reindirizzamento può certamente aggiungere una latenza indesiderata a una richiesta di navigazione, ma la situazione può peggiorare se il reindirizzamento punta a un'altra risorsa che comporta un altro reindirizzamento e così via. Ciò può influire in particolare sui siti che ricevono un volume elevato di visitatori da pubblicità o newsletter, poiché spesso reindirizzano tramite servizi di analisi per scopi di misurazione. L'eliminazione dei reindirizzamenti sotto il tuo controllo diretto può contribuire a ottenere un buon TTFB.
Esistono due tipi di reindirizzamenti:
- Reindirizzamenti con stessa origine, in cui il reindirizzamento avviene interamente sul tuo sito web.
- Reindirizzamenti multiorigine, in cui il reindirizzamento si verifica inizialmente su un'altra origine, ad esempio da un servizio di abbreviazione degli URL dei social media, prima di arrivare al tuo sito web.
Ti consigliamo di concentrarti sull'eliminazione dei reindirizzamenti dalla stessa origine, in quanto si tratta di un aspetto su cui avrai il controllo diretto. Ciò comporta il controllo dei link sul tuo sito web per verificare se qualcuno di questi restituisce un codice di risposta 302 o 301. Spesso questo può essere il risultato della mancata inclusione dello schema https:// (quindi i browser utilizzano http:// per impostazione predefinita, che poi reindirizza) o perché le barre finali non sono incluse o escluse correttamente nell'URL.
I reindirizzamenti multiorigine sono più difficili da gestire, in quanto spesso non sono sotto il tuo controllo, ma cerca di evitare reindirizzamenti multipli, ad esempio utilizzando più servizi di abbreviazione dei link quando li condividi. Assicurati che l'URL fornito agli inserzionisti o alle newsletter sia l'URL finale corretto, in modo da non aggiungere un altro reindirizzamento a quelli utilizzati da questi servizi.
Un'altra importante fonte di tempo di reindirizzamento può derivare dai reindirizzamenti da HTTP a HTTPS. Un modo per aggirare questo problema è utilizzare l'intestazione Strict-Transport-Security (HSTS), che impone l'utilizzo di HTTPS alla prima visita di un'origine e poi indica al browser di accedere immediatamente all'origine tramite lo schema HTTPS nelle visite future.
Una volta implementata una buona norma HSTS, puoi velocizzare le operazioni alla prima visita di un'origine aggiungendo il tuo sito all'elenco di precaricamento HSTS.
Trasmettere il markup dello stream al browser
I browser sono ottimizzati per elaborare il markup in modo efficiente quando viene trasmesso in streaming, il che significa che il markup viene gestito in blocchi man mano che arriva dal server. Ciò è fondamentale per i payload di markup di grandi dimensioni, in quanto significa che il browser può analizzare i blocchi di markup in modo incrementale, anziché attendere l'arrivo dell'intera risposta prima di iniziare l'analisi.
Sebbene i browser siano ottimi nella gestione del markup di streaming, è fondamentale fare tutto il possibile per mantenere il flusso in modo che i bit iniziali del markup vengano inviati il prima possibile. Se il backend sta rallentando le operazioni, è un problema. Poiché gli stack di backend sono numerosi, non rientra nell'ambito di questa guida trattare ogni singolo stack e i problemi che potrebbero sorgere in ognuno di essi.
React, ad esempio, e altri framework che possono eseguire il rendering del markup on demand sul server, hanno utilizzato un approccio sincrono al rendering lato server. Tuttavia, le versioni più recenti di React hanno implementato metodi server per lo streaming del markup durante il rendering. Ciò significa che non devi attendere che un metodo API del server React esegua il rendering dell'intera risposta prima che venga inviata.
Un altro modo per assicurarsi che il markup venga trasmesso rapidamente al browser è fare affidamento al rendering statico, che genera file HTML durante la compilazione. Con il file completo disponibile immediatamente, i server web possono iniziare a inviarlo subito e la natura intrinseca di HTTP comporterà il markup dello streaming. Sebbene questo approccio non sia adatto a tutte le pagine di tutti i siti web, ad esempio quelle che richiedono una risposta dinamica nell'ambito dell'esperienza utente, può essere utile per le pagine che non richiedono che il markup venga personalizzato per un utente specifico.
Utilizzare un service worker
L'API Service Worker può avere un grande impatto sul TTFB sia per i documenti sia per le risorse che caricano. Il motivo è che un service worker funge da proxy tra il browser e il server, ma l'impatto sul TTFB del tuo sito web dipende da come configuri il service worker e se questa configurazione è in linea con i requisiti della tua applicazione.
- Utilizza una strategia di rivalidazione non aggiornata per gli asset. Se una risorsa si trova nella cache del service worker, che si tratti di un documento o di una risorsa richiesta dal documento, la strategia stale-while-revalidate servirà prima la risorsa dalla cache, poi la scaricherà in background e la servirà dalla cache per le interazioni future.
- Se hai risorse di documenti che non cambiano molto spesso, l'utilizzo di una strategia stale-while-revalidate può rendere quasi istantaneo il TTFB di una pagina. Tuttavia, questo non funziona bene se il tuo sito web invia markup generato dinamicamente, ad esempio markup che cambia in base all'autenticazione di un utente. In questi casi, ti consigliamo di accedere prima alla rete, in modo che il documento sia il più aggiornato possibile.
- Se il documento carica risorse non critiche che cambiano con una certa frequenza, ma il recupero della risorsa obsoleta non influisce in modo significativo sull'esperienza utente, ad esempio immagini selezionate o altre risorse non critiche, il TTFB per queste risorse può essere notevolmente ridotto utilizzando una strategia stale-while-revalidate.
- Utilizza il modello di shell dell'app per le applicazioni sottoposte a rendering lato client. Questo modello è più adatto alle SPA in cui la "shell" della pagina può essere pubblicata immediatamente dalla cache del service worker e i contenuti dinamici della pagina vengono compilati e visualizzati in un secondo momento nel ciclo di vita della pagina.
Utilizza 103 Early Hints per le risorse critiche per il rendering
Indipendentemente dal livello di ottimizzazione del backend dell'applicazione, il server potrebbe dover svolgere ancora una notevole quantità di lavoro per preparare una risposta, incluso il lavoro costoso (ma necessario) del database che ritarda l'arrivo della risposta di navigazione. L'effetto potenziale è che alcune risorse successive fondamentali per il rendering potrebbero essere ritardate, come CSS o, in alcuni casi, JavaScript che esegue il rendering del markup sul client.
L'intestazione 103 Early Hints è un codice di risposta iniziale che il server può inviare al browser mentre il backend è occupato a preparare il markup. Questa intestazione può essere utilizzata per suggerire al browser che esistono risorse di rendering critiche che la pagina deve iniziare a scaricare mentre viene preparato il markup. Per i browser supportati, l'effetto può essere un rendering più rapido dei documenti (CSS) e un caricamento più veloce delle pagine.
Uno svantaggio di 103 Early Hints è che, come la memorizzazione nella cache, può mascherare il TTFB "reale" di un sito. Se un'infrastruttura server è lenta (perché è sottodimensionata o il codice deve essere ottimizzato), questo può essere meno evidente quando viene utilizzato 103 Early Hints, poiché il TTFB sembra veloce. I siti che utilizzano 103 Early Hints devono prendere in considerazione la misurazione del tempo effettivo del server (anche se Server-Timing o finalResponseHeadersStart dell'API PerformanceNavigationTiming).
Conclusione
Poiché esistono così tante combinazioni di stack di applicazioni di backend, non esiste un unico articolo che possa riassumere tutto ciò che puoi fare per ridurre il TTFB del tuo sito web. Tuttavia, ecco alcune opzioni che puoi esplorare per provare ad accelerare un po' le cose sul lato server.
Come per l'ottimizzazione di ogni metrica, l'approccio è in gran parte simile: misura il TTFB sul campo, utilizza gli strumenti di laboratorio per analizzare in dettaglio le cause e poi applica le ottimizzazioni ove possibile. Non tutte le tecniche descritte qui potrebbero essere fattibili per la tua situazione, ma alcune lo saranno. Come sempre, dovrai monitorare attentamente i dati sul campo e apportare le modifiche necessarie per garantire l'esperienza utente più rapida possibile.
Immagine hero di Taylor Vick, tratta da Unsplash.