
Saiba como otimizar para a métrica "Tempo até o primeiro byte".


O Tempo até o primeiro byte (TTFB) é uma métrica fundamental de desempenho da Web que precede todas as outras métricas significativas de experiência do usuário, como First Contentful Paint (FCP) e Largest Contentful Paint (LCP). Isso significa que valores altos de TTFB adicionam tempo às métricas que vêm depois.
Recomendamos que o servidor responda às solicitações de navegação com rapidez suficiente para que o 75º percentil de usuários tenha um FCP dentro do limite "bom". Como uma orientação geral, a maioria dos sites deve ter um TTFB de 0,8 segundo ou menos.

Como medir o TTFB
Antes de otimizar o TTFB, observe como ele afeta os usuários do seu site. Você deve usar dados de campo como fonte principal para observar o TTFB afetado por redirecionamentos. Já as ferramentas baseadas em laboratório geralmente são medidas usando o URL final, perdendo esse atraso extra.
O PageSpeed Insights é uma maneira de receber informações de campo e de laboratório para sites públicos disponíveis no Chrome User Experience Report.
O TTFB para usuários reais é mostrado na seção superior Entender a experiência dos seus usuários:
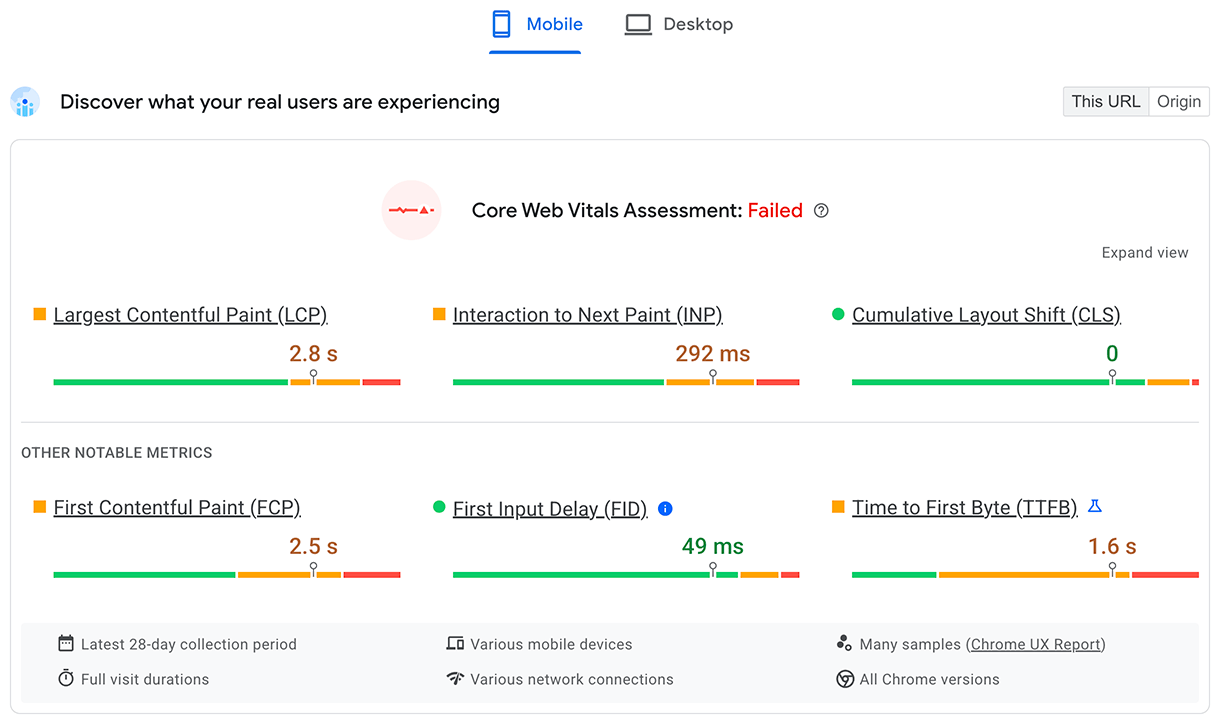
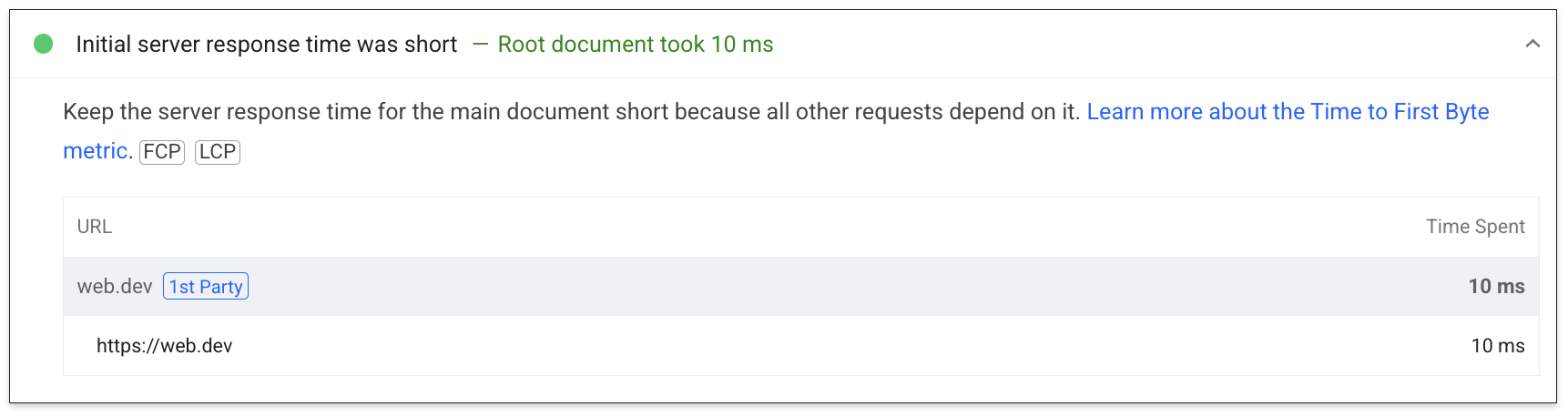
Para dados de laboratório, um subconjunto do TTFB é mostrado na auditoria de tempo de resposta do servidor:
Para saber mais maneiras de medir o TTFB no campo e no laboratório, consulte a página da métrica TTFB.
Entender as diferenças entre o TTFB de campo e de laboratório
O TTFB de laboratório e de campo podem ser diferentes por vários motivos. Quando isso acontece, é importante entender o motivo para usar os dados de laboratório de maneira eficaz e melhorar as experiências dos usuários.
Quando o TTFB do laboratório é muito maior do que o TTFB do campo, isso indica que o ambiente do laboratório é mais restrito do que as experiências típicas do usuário. Isso não é necessariamente um problema, já que os resultados e as recomendações do laboratório provavelmente ainda serão válidos, mas podem exagerar o impacto e a melhoria.
Quando o TTFB de campo é muito maior do que o TTFB de laboratório, isso indica problemas não aparentes durante a execução no laboratório, como o uso de cache do lado do servidor, redirecionamentos ou diferenças de rede. Nesse caso, os resultados e as recomendações do laboratório podem ser menos úteis, já que não vão abordar um dos principais problemas.
Para saber se o cache do lado do servidor está afetando o TTFB do laboratório, teste páginas menos comuns ou use parâmetros de URL diferentes para receber conteúdo não armazenado em cache e verificar se o TTFB está mais alinhado com o TTFB de campo. Também pode ser útil ter a capacidade de ignorar o cache do lado do servidor com um parâmetro de URL específico. Consulte a seção de conteúdo em cache.
Para redirecionamentos e diferenças de rede, a análise de como e de onde o tráfego está chegando ao nosso site pode ser útil para diagnosticar se esses são problemas em potencial.
Depurar TTFB alto no campo com Server-Timing
O cabeçalho de resposta Server-Timing pode ser usado no back-end do aplicativo para medir processos distintos que podem contribuir para uma alta latência. A estrutura do valor do cabeçalho é flexível e aceita, no mínimo, um identificador definido por você. Os valores opcionais incluem um valor de duração (via dur) e uma descrição opcional legível (via desc).
O Serving-Timing pode ser usado para medir muitos processos de back-end de aplicativos, mas há alguns que merecem atenção especial:
- Consultas de banco de dados
- Tempo de renderização do lado do servidor, se aplicável
- Buscas de disco
- Acertos ou erros de cache do servidor de borda (se estiver usando uma CDN)
Todas as partes de uma entrada Server-Timing são separadas por dois-pontos, e várias entradas podem ser separadas por uma vírgula:
// Two metrics with descriptions and values
Server-Timing: db;desc="Database";dur=121.3, ssr;desc="Server-side Rendering";dur=212.2
O cabeçalho pode ser definido usando a linguagem de preferência do back-end do aplicativo. Em PHP, por exemplo, você pode definir o cabeçalho assim:
<?php
// Get a high-resolution timestamp before
// the database query is performed:
$dbReadStartTime = hrtime(true);
// Perform a database query and get results...
// ...
// Get a high-resolution timestamp after
// the database query is performed:
$dbReadEndTime = hrtime(true);
// Get the total time, converting nanoseconds to
// milliseconds (or whatever granularity you need):
$dbReadTotalTime = ($dbReadEndTime - $dbReadStartTime) / 1e+6;
// Set the Server-Timing header:
header('Server-Timing: db;desc="Database";dur=' . $dbReadTotalTime);
?>
Quando esse cabeçalho é definido, ele mostra informações que podem ser usadas tanto no laboratório quanto no campo.
No campo, qualquer página com um cabeçalho de resposta Server-Timing definido vai preencher a propriedade serverTiming na API Navigation Timing:
// Get the serverTiming entry for the first navigation request:
performance.getEntries('navigation')[0].serverTiming.forEach(entry => {
// Log the server timing data:
console.log(entry.name, entry.description, entry.duration);
});
No laboratório, os dados do cabeçalho de resposta Server-Timing serão visualizados no painel de tempos da guia Rede no Chrome DevTools:

Cabeçalhos de resposta Server-Timing visualizados na guia "Rede" do Chrome DevTools. Aqui, Server-Timing é usado para medir se uma solicitação de um recurso atingiu o cache da CDN e quanto tempo leva para que a solicitação atinja o servidor de borda da CDN e, em seguida, a origem.
Depois de determinar que você tem um TTFB problemático analisando os dados disponíveis, é possível corrigir o problema.
Maneiras de otimizar o TTFB
O aspecto mais desafiador da otimização do TTFB é que, embora a pilha de front-end da Web seja sempre HTML, CSS e JavaScript, as pilhas de back-end podem variar muito. Há várias stacks de back-end e produtos de banco de dados, cada um com suas próprias técnicas de otimização. Portanto, este guia vai se concentrar no que se aplica à maioria das arquiteturas, em vez de focar apenas em orientações específicas da pilha.
Orientações específicas da plataforma
A plataforma usada no seu site pode afetar muito o TTFB. Por exemplo, o desempenho do WordPress é afetado pelo número e pela qualidade dos plug-ins ou pelos temas usados. Outras plataformas são afetadas da mesma forma quando são personalizadas. Consulte a documentação da sua plataforma para receber conselhos específicos do fornecedor e complementar as dicas de desempenho mais gerais deste post. A auditoria do Lighthouse para reduzir os tempos de resposta do servidor também inclui algumas orientações específicas da pilha limitadas.
Hospedagem, hospedagem, hospedagem
Antes de considerar outras abordagens de otimização, a hospedagem deve ser a primeira coisa a ser considerada. Não há muitas orientações específicas que possam ser oferecidas aqui, mas uma regra geral é garantir que o host do seu site seja capaz de lidar com o tráfego enviado a ele.
A hospedagem compartilhada geralmente é mais lenta. Se você estiver executando um pequeno site pessoal que serve principalmente arquivos estáticos, isso provavelmente não será um problema, e algumas das técnicas de otimização a seguir vão ajudar a reduzir o TTFB o máximo possível.
No entanto, se você estiver executando um aplicativo maior com muitos usuários que envolve personalização, consultas de banco de dados e outras operações intensivas do lado do servidor, a escolha da hospedagem será fundamental para reduzir o TTFB no campo.
Ao escolher um provedor de hospedagem, fique de olho nestes aspectos:
- Quanta memória a instância do aplicativo tem alocada? Se o aplicativo não tiver memória suficiente, ele vai gerar thrashing e ter dificuldades para veicular páginas o mais rápido possível.
- Seu provedor de hospedagem mantém sua pilha de back-end atualizada? À medida que novas versões de linguagens de back-end de aplicativos, implementações HTTP e software de banco de dados são lançadas, o desempenho desses softwares melhora com o tempo. É fundamental fazer parceria com um provedor de hospedagem que priorize esse tipo de manutenção crucial.
- Se você tiver requisitos de aplicativo muito específicos e quiser o acesso de nível mais baixo aos arquivos de configuração do servidor, pergunte se faz sentido personalizar o back-end da sua própria instância de aplicativo.
Há muitos provedores de hospedagem que cuidam dessas coisas para você, mas se você começar a observar valores longos de TTFB mesmo em provedores de hospedagem dedicados, isso pode ser um sinal de que você precisa reavaliar os recursos do seu provedor de hospedagem atual para oferecer a melhor experiência possível ao usuário.
Use uma rede de fornecimento de conteúdo (CDN)
O tema uso de CDN é muito conhecido, mas por um bom motivo: você pode ter um back-end de aplicativo muito bem otimizado, mas os usuários localizados longe do seu servidor de origem ainda podem ter um TTFB alto no campo.
As CDNs resolvem o problema da proximidade do usuário com o servidor de origem usando uma rede distribuída de servidores que armazenam recursos em cache em servidores fisicamente mais próximos dos usuários. Esses servidores são chamados de servidores de borda.
Os provedores de CDN também podem oferecer benefícios além dos servidores de borda:
- Os provedores de CDN geralmente oferecem tempos de resolução de DNS extremamente rápidos.
- Uma CDN provavelmente vai disponibilizar seu conteúdo de servidores de borda usando protocolos modernos, como HTTP/2 ou HTTP/3.
- O HTTP/3, em particular, resolve o problema de bloqueio de início de linha presente no TCP (em que o HTTP/2 se baseia) usando o protocolo UDP.
- Uma CDN também pode fornecer versões modernas do TLS, o que reduz a latência envolvida no tempo de negociação do TLS. O TLS 1.3, em particular, foi projetado para manter a negociação do TLS o mais curta possível.
- Alguns provedores de CDN oferecem um recurso geralmente chamado de "edge worker", que usa uma API semelhante à API Service Worker para interceptar solicitações, gerenciar respostas de maneira programática em caches de borda ou reescrever respostas completamente.
- Os provedores de CDN são muito bons em otimizar a compactação. A compactação é difícil de fazer por conta própria e pode levar a tempos de resposta mais lentos em determinados casos com marcação gerada dinamicamente, que precisa ser compactada na hora.
- Os provedores de CDN também armazenam em cache automaticamente as respostas compactadas para recursos estáticos, resultando na melhor combinação de taxa de compactação e tempo de resposta.
Embora a adoção de uma CDN envolva um esforço variável, de trivial a significativo, ela deve ser uma prioridade alta para otimizar o TTFB se o site ainda não estiver usando uma.
Usar conteúdo armazenado em cache sempre que possível
As CDNs permitem que o conteúdo seja armazenado em cache em servidores de borda, que estão fisicamente mais próximos dos visitantes, desde que o conteúdo seja configurado com os cabeçalhos HTTP Cache-Control adequados. Embora isso não seja adequado para conteúdo personalizado, exigir uma viagem de volta à origem pode negar grande parte do valor de uma CDN.
Para sites que atualizam o conteúdo com frequência, mesmo um tempo de armazenamento em cache curto pode resultar em ganhos de desempenho notáveis para sites movimentados. Isso porque apenas o primeiro visitante durante esse período passa pela latência total de volta ao servidor de origem, enquanto todos os outros visitantes podem reutilizar o recurso em cache do servidor de borda. Algumas CDNs permitem a invalidação do cache em lançamentos de sites, oferecendo o melhor dos dois mundos: tempos de cache longos, mas atualizações instantâneas quando necessário.
Mesmo quando o armazenamento em cache está configurado corretamente, isso pode ser ignorado usando parâmetros de string de consulta exclusivos para medição de análise. Para a CDN, eles podem parecer conteúdos diferentes, mesmo sendo iguais. Por isso, a versão em cache não será usada.
Conteúdo mais antigo ou menos visitado também pode não ser armazenado em cache, o que pode resultar em valores de TTFB mais altos em algumas páginas do que em outras. Aumentar os tempos de armazenamento em cache pode reduzir o impacto disso, mas saiba que, com o aumento dos tempos de armazenamento em cache, há uma maior possibilidade de veicular conteúdo potencialmente desatualizado.
O impacto do conteúdo em cache não afeta apenas quem usa CDNs. A infraestrutura do servidor pode precisar gerar conteúdo de pesquisas caras no banco de dados quando o conteúdo armazenado em cache não pode ser reutilizado. Dados acessados com mais frequência ou páginas pré-armazenadas em cache geralmente têm uma performance melhor.
Evite redirecionamentos múltiplos de página
Um fator comum para um TTFB alto são os redirecionamentos. Os redirecionamentos ocorrem quando uma solicitação de navegação para um documento recebe uma resposta que informa ao navegador que o recurso existe em outro local. Um redirecionamento pode adicionar uma latência indesejada a uma solicitação de navegação, mas a situação pode piorar se ele apontar para outro recurso que resulte em outro redirecionamento, e assim por diante. Isso pode afetar principalmente sites que recebem grandes volumes de visitantes de anúncios ou newsletters, já que eles geralmente redirecionam por serviços de análise para fins de medição. Eliminar redirecionamentos sob seu controle direto pode ajudar a alcançar um bom TTFB.
Há dois tipos de redirecionamentos:
- Redirecionamentos de mesma origem, em que o redirecionamento ocorre totalmente no seu site.
- Redirecionamentos de origem cruzada, em que o redirecionamento ocorre inicialmente em outra origem, como um serviço de encurtamento de URL de redes sociais, por exemplo, antes de chegar ao seu site.
Você quer se concentrar em eliminar redirecionamentos da mesma origem, já que isso é algo que você pode controlar diretamente. Isso envolve verificar os links no seu site para ver se algum deles resulta em um código de resposta 302 ou 301. Muitas vezes, isso acontece porque o esquema https:// não foi incluído (então os navegadores usam http:// por padrão, que redireciona) ou porque as barras finais não foram incluídas ou excluídas corretamente no URL.
Os redirecionamentos de origem cruzada são mais complicados, já que geralmente estão fora do seu controle. No entanto, tente evitar vários redirecionamentos sempre que possível. Por exemplo, use vários encurtadores de links ao compartilhar links. Verifique se o URL fornecido a anunciantes ou newsletters é o URL final correto para não adicionar outro redirecionamento aos usados por esses serviços.
Outra fonte importante de tempo de redirecionamento pode vir de redirecionamentos de HTTP para HTTPS. Uma maneira de contornar isso é usar o cabeçalho Strict-Transport-Security (HSTS), que vai forçar o HTTPS na primeira visita a uma origem e, em seguida, vai dizer ao navegador para acessar imediatamente a origem pelo esquema HTTPS em visitas futuras.
Depois de implementar uma boa política de HSTS, você pode acelerar as coisas na primeira visita a uma origem adicionando seu site à lista de pré-carregamento de HSTS.
Transmitir marcação para o navegador
Os navegadores são otimizados para processar a marcação de forma eficiente quando ela é transmitida, ou seja, a marcação é processada em partes à medida que chega do servidor. Isso é crucial quando se trata de payloads de marcação grandes, porque significa que o navegador pode analisar os blocos de marcação de forma incremental, em vez de esperar que toda a resposta chegue antes de iniciar a análise.
Embora os navegadores sejam ótimos para lidar com a marcação de streaming, é fundamental fazer tudo o que for possível para manter esse fluxo. Assim, os bits iniciais de marcação são enviados o mais rápido possível. Se o back-end estiver atrasando as coisas, isso é um problema. Como há muitas stacks de back-end, este guia não aborda todas elas e os problemas que podem surgir em cada uma.
O React, por exemplo, e outros frameworks que podem renderizar marcação sob demanda no servidor usam uma abordagem síncrona para a renderização do lado do servidor. No entanto, versões mais recentes do React implementaram métodos de servidor para streaming de marcação à medida que ela é renderizada. Isso significa que você não precisa esperar que um método da API do servidor React renderize toda a resposta antes de enviá-la.
Outra maneira de garantir que a marcação seja transmitida rapidamente para o navegador é usar a renderização estática, que gera arquivos HTML durante o tempo de build. Com o arquivo completo disponível imediatamente, os servidores da Web podem começar a enviar o arquivo imediatamente, e a natureza inerente do HTTP resultará em marcação de streaming. Embora essa abordagem não seja adequada para todas as páginas de todos os sites, como aquelas que exigem uma resposta dinâmica como parte da experiência do usuário, ela pode ser benéfica para páginas que não precisam de marcação para serem personalizadas para um usuário específico.
Usar um service worker
A API Service Worker pode ter um grande impacto no TTFB de documentos e dos recursos que eles carregam. Isso acontece porque um service worker atua como um proxy entre o navegador e o servidor. No entanto, o impacto no TTFB do seu site depende de como você configura o service worker e se essa configuração está alinhada aos requisitos do aplicativo.
- Use uma estratégia de atualização em segundo plano para recursos. Se um recurso estiver no cache do service worker, seja um documento ou um recurso exigido pelo documento, a estratégia stale-while-revalidate vai veicular esse recurso primeiro do cache, depois vai baixar o recurso em segundo plano e veicular do cache para interações futuras.
- Se você tiver recursos de documentos que não mudam com muita frequência, usar uma estratégia de atualização em segundo plano pode tornar o TTFB de uma página quase instantâneo. No entanto, isso não funciona tão bem se o site enviar marcação gerada dinamicamente, como marcação que muda com base na autenticação de um usuário. Nesses casos, é sempre melhor acessar a rede primeiro para que o documento esteja o mais atualizado possível.
- Se o documento carregar recursos não críticos que mudam com alguma frequência, mas buscar o recurso desatualizado não afetar muito a experiência do usuário (como imagens selecionadas ou outros recursos não críticos), o TTFB desses recursos poderá ser muito reduzido usando uma estratégia de atualização em segundo plano.
- Use o modelo de shell do app para aplicativos renderizados pelo cliente. Esse modelo é mais adequado para SPAs em que o "shell" da página pode ser entregue instantaneamente do cache do service worker, e o conteúdo dinâmico da página é preenchido e renderizado mais tarde no ciclo de vida da página.
Usar 103 Early Hints para recursos essenciais para a renderização
Não importa o quanto o back-end do aplicativo esteja otimizado, ainda pode haver uma quantidade significativa de trabalho que o servidor precisa fazer para preparar uma resposta, incluindo um trabalho caro (mas necessário) de banco de dados que atrasa a chegada da resposta de navegação o mais rápido possível. O efeito potencial disso é que alguns recursos críticos de renderização subsequentes podem ser atrasados, como CSS ou, em alguns casos, JavaScript que renderiza marcação no cliente.
O cabeçalho 103 Early Hints é um código de resposta inicial que o servidor pode enviar ao navegador enquanto o back-end está ocupado preparando a marcação. Esse cabeçalho pode ser usado para sugerir ao navegador que há recursos essenciais para renderização que a página precisa começar a baixar enquanto a marcação está sendo preparada. Para navegadores compatíveis, o efeito pode ser uma renderização de documentos mais rápida (CSS) e um carregamento de página mais rápido.
Uma desvantagem das dicas antecipadas 103 é que, assim como o armazenamento em cache, elas podem mascarar o TTFB "real" de um site. Se uma infraestrutura de servidor for lenta (por falta de energia ou porque o código precisa ser otimizado), isso pode ficar menos óbvio quando as dicas iniciais 103 são usadas, já que o TTFB parece rápido. Sites que usam 103 Early Hints precisam medir o tempo real do servidor (com Server-Timing ou finalResponseHeadersStart da API PerformanceNavigationTiming).
Conclusão
Como há muitas combinações de stacks de aplicativos de back-end, não existe um artigo que possa encapsular tudo o que você pode fazer para diminuir o TTFB do seu site. No entanto, estas são algumas opções que você pode explorar para tentar acelerar um pouco as coisas no lado do servidor.
Assim como na otimização de qualquer métrica, a abordagem é muito parecida: meça o TTFB no campo, use ferramentas de laboratório para detalhar as causas e aplique otimizações sempre que possível. Nem todas as técnicas aqui podem ser viáveis para sua situação, mas algumas serão. Como sempre, é necessário acompanhar de perto os dados de campo e fazer ajustes conforme necessário para garantir a experiência do usuário mais rápida possível.
Imagem principal de Taylor Vick, do Unsplash.