

Published: January 30, 2025
Many WebAssembly applications on the web benefit from multithreading, in the same way as native applications. Multiple threads let more work happen in parallel, and shift heavy work off the main thread to avoid latency issues. Until recently, there were some common pain points that could happen with such multithreaded applications, related to allocations and I/O. Luckily, recent features in Emscripten can help a lot with those issues. This guide shows how these features can lead to speed improvements of 10 times or more in some cases.
Scaling
The following graph shows efficient multithreaded scaling in a pure math workload (from the benchmark we'll be using in this article):
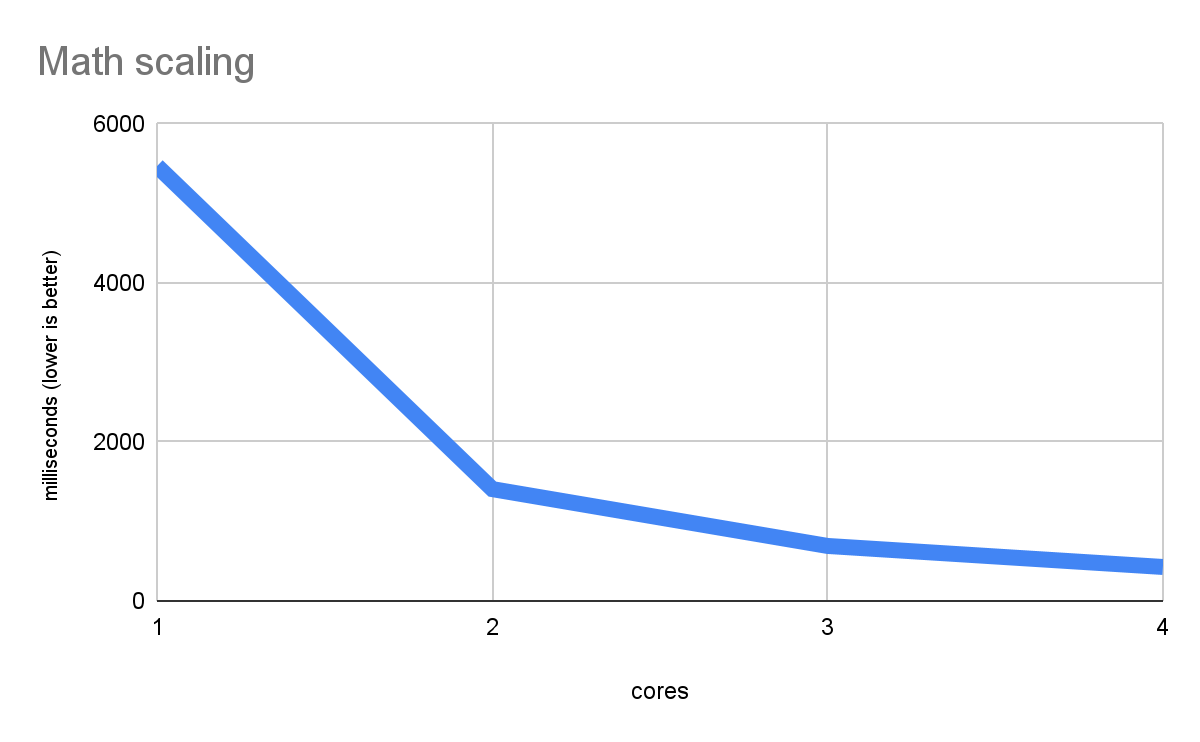
This measures pure computation, something which each CPU core can do on its own, so performance improves with more cores. Such a descending line of faster performance is exactly what good scaling looks like. And it shows that the web platform can execute multithreaded native code very well, despite using web workers as the basis for parallelism, using Wasm rather than true native code, and other details that might seem less optimal.
Heap management: malloc/free
malloc and free are critical standard library functions in all linear-memory
languages (for example, C, C++, Rust, and Zig) relied upon for managing all
memory that is not fully static or on the stack. Emscripten uses dlmalloc by
default, which is a compact but efficient implementation (it also supports
emmalloc, which
is even more compact but slower in some cases). However, the multithreaded
performance of dlmalloc is limited because it takes a lock on each
malloc/free (because there is a single global allocator). Therefore, you
can run into contention and slowness if you have many allocations in many
threads at once. Here's what happens when you run an incredibly malloc-heavy
benchmark:
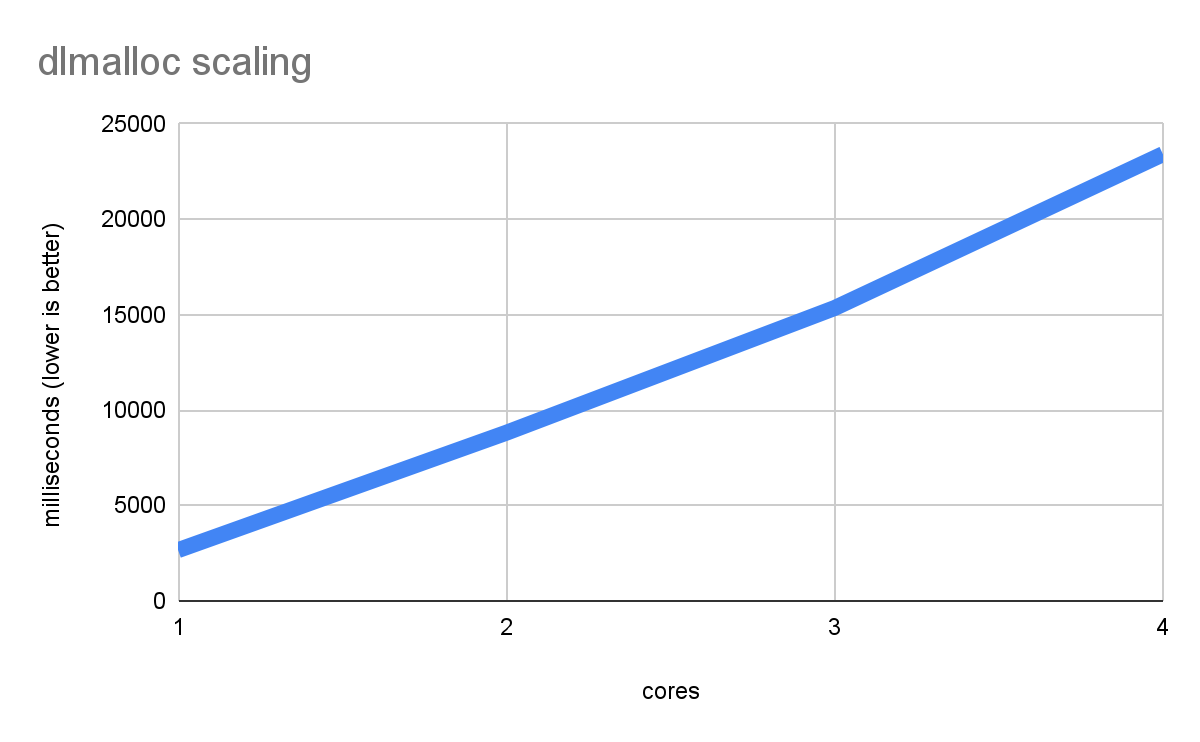
Not only does performance not improve with more cores, but it gets worse and
worse, as each thread ends up waiting for long periods of time for the malloc
lock. This is the very worst case possible, but it can happen in real workloads
if there are enough allocations.
mimalloc
Multithreaded-optimized versions of dlmalloc exist, like ptmalloc3, which
implements a separate allocator instance per thread, avoiding contention.
Several other allocators exist with multithreading optimizations, like
jemalloc and tcmalloc. Emscripten decided to focus on the recent
mimalloc project, which is a
nicely-designed allocator from Microsoft with very good portability and
performance. Use it as follows:
emcc -sMALLOC=mimalloc
Here are the results for the malloc benchmark using mimalloc:
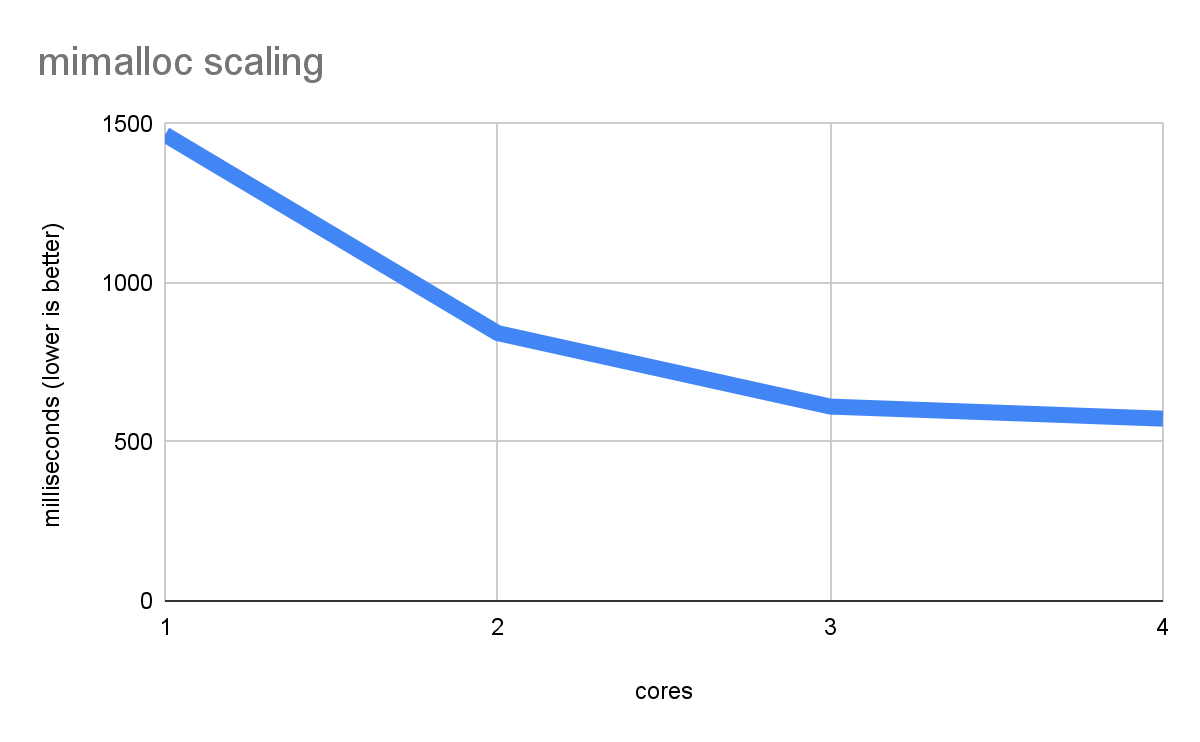
Perfect! Now performance scales efficiently, getting faster and faster with each core.
If you look carefully at the data for single-core performance in the last
two graphs, you'll see that dlmalloc took 2660 ms and mimalloc only 1466, a
nearly 2 time speed improvement. That shows that even on a single-threaded
application you may see benefits from mimalloc's more sophisticated
optimizations, though note that it does come at a cost in code size and memory
usage (for that reason, dlmalloc remains the default).
Files and I/O
Many applications need to use files for various reasons. For example, to load
levels in a game, or fonts in an image editor. Even an operation like printf
uses the file system under the hood, because it prints by writing data to
stdout.
In single-threaded applications, this is usually not an issue, and Emscripten
will automatically avoid linking in full file system support if all you need is
printf. However, if you do use files, then multithreaded file system access is
tricky as file access must be synchronized between threads. The original
file system implementation in Emscripten, called "JS FS" because it was
implemented in JavaScript, used the simple model of implementing the file system
only on the main thread. Whenever another thread wants to access a file, it
proxies a request to the main thread. This means that the other thread blocks on
a cross-thread request, which the main thread eventually handles.
This simple model is optimal if only the main thread accesses files, which is a common pattern. However, if other threads do reads and writes, then problems happen. First, the main thread ends up doing work for other threads causing user-visible latency. Then, background threads end up waiting for the main thread to be free in order to do the work they need, so things get slower (or, worse, you can end up in a deadlock if the main thread is currently waiting on that worker thread).
WasmFS
To fix this problem, Emscripten has a new file system implementation, WasmFS. WasmFS is written in C++ and compiled to Wasm, unlike the original file system which was in JavaScript. WasmFS supports file system access from multiple threads with minimal overhead, by storing the files in Wasm linear memory, which is shared between all threads. All threads can now do file I/O with equal performance, and often they can even avoid blocking each other.
A simple file system benchmark shows the huge advantage of WasmFS compared to the old JS FS.
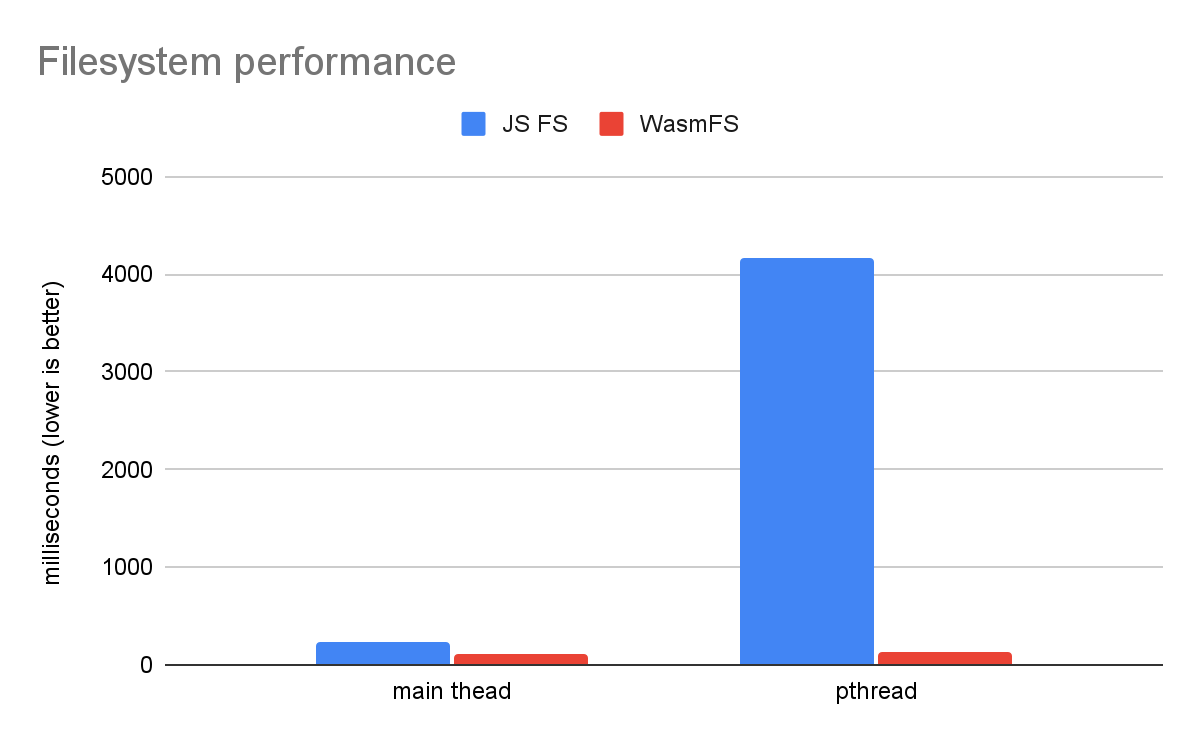
This compares running file system code directly on the main thread to running it on a single pthread. In the old JS FS, every file system operation must be proxied to the main thread, which makes it over an order of magnitude slower on a pthread! That's because rather than just read/write some bytes, the JS FS does cross-thread communication, which involves locks, a queue, and waiting. In contrast, WasmFS can access files from any thread equally, and so the chart shows that there is practically no difference between the main thread and a pthread. As a result, WasmFS is 32 times faster than the JS FS when on a pthread.
Note that there is also a difference on the main thread where WasmFS is 2 times faster. That's because the JS FS calls out to JavaScript for every file system operation, which WasmFS avoids. WasmFS only uses JavaScript when necessary (for example, to use a Web API), which leaves most WasmFS files in Wasm. Also, even when JavaScript is required, WasmFS can use a helper thread rather than the main thread, to avoid user-visible latency. Because of this you may see speed improvements from using WasmFS even if your application is not multithreaded (or if it is multithreaded but uses files only on the main thread).
Use WasmFS as follows:
emcc -sWASMFS
WasmFS is used in production and considered stable, but it doesn't yet support all the features of the old JS FS. On the other hand, it does include some important new features like support for the origin private file system (OPFS, which is highly recommended for persistent storage). Unless you happen to need a feature that hasn't been ported yet, the Emscripten team recommends using WasmFS.
Conclusion
If you have a multithreaded application that does lots of allocations or uses
files, then you may benefit greatly by using WasmFS and/or mimalloc. Both are
simple to try in an Emscripten project by just recompiling with the flags
described in this post.
You may even want to try those features if you aren't using threads: As mentioned earlier, the more modern implementations come with optimizations that are noticeable even on a single core in some cases.