
O padrão do sistema de arquivos apresenta um sistema de arquivos privado de origem (OPFS, na sigla em inglês) como um endpoint de armazenamento privado para a origem da página e não visível para o usuário, que oferece acesso opcional a um tipo especial de arquivo altamente otimizado para desempenho.

Suporte ao navegador
O sistema de arquivos privado de origem é compatível com navegadores modernos e padronizado pelo grupo de trabalho de tecnologia de aplicativos de hipertexto da Web (WHATWG) no Padrão ativo do sistema de arquivos (em inglês).
' d='M96 183a64 64 0 0 1-23-23L17 64a128 128 0 0 0 111 192l55-96a64 64 0 0 1-87 23Z'/%3E%3Cpath fill='url(%23b)' d='M192 128a64 64 0 0 1-9 32l-55 96A128 128 0 0 0 239 64H128a64 64 0 0 1 64 64Z'/%3E%3Ccircle cx='128' cy='128' r='52' fill='%231a73e8'/%3E%3Cpath fill='url(%23c)' d='M96 73a64 64 0 0 1 32-9h111a128 128 0 0 0-222 0l56 96a64 64 0 0 1 23-87Z'/%3E%3C/svg%3E)
' xlink:href='%23A'%3E%3Cstop offset='.76' stop-opacity='0'/%3E%3Cstop offset='.95' stop-opacity='.5'/%3E%3Cstop offset='1'/%3E%3C/radialGradient%3E%3CradialGradient id='F' cx='2523' cy='4680' r='20243' gradientTransform='matrix(-.03715 .99931 -2.12836 -.07913 13579 3530)' xlink:href='%23A'%3E%3Cstop offset='0' stop-color='%2335c1f1'/%3E%3Cstop offset='.11' stop-color='%2334c1ed'/%3E%3Cstop offset='.23' stop-color='%232fc2df'/%3E%3Cstop offset='.31' stop-color='%232bc3d2'/%3E%3Cstop offset='.67' stop-color='%2336c752'/%3E%3C/radialGradient%3E%3CradialGradient id='G' cx='24247' cy='7758' r='9734' gradientTransform='matrix(.28109 .95968 -.78353 .22949 24510 -16292)' xlink:href='%23A'%3E%3Cstop offset='0' stop-color='%2366eb6e'/%3E%3Cstop offset='1' stop-color='%2366eb6e' stop-opacity='0'/%3E%3C/radialGradient%3E%3Cpath id='H' d='M24105 20053a9345 9345 0 01-1053 472 10202 10202 0 01-3590 646c-4732 0-8855-3255-8855-7432 0-1175 680-2193 1643-2729-4280 180-5380 4640-5380 7253 0 7387 6810 8137 8276 8137 791 0 1984-230 2704-456l130-44a12834 12834 0 006660-5282c220-350-168-757-535-565z'/%3E%3Cpath id='I' d='M11571 25141a7913 7913 0 01-2273-2137 8145 8145 0 01-1514-4740 8093 8093 0 013093-6395 8082 8082 0 011373-859c312-148 846-414 1554-404a3236 3236 0 012569 1297 3184 3184 0 01636 1866c0-21 2446-7960-8005-7960-4390 0-8004 4166-8004 7820 0 2319 538 4170 1212 5604a12833 12833 0 007684 6757 12795 12795 0 003908 610c1414 0 2774-233 4045-656a7575 7575 0 01-6278-803z'/%3E%3Cpath id='J' d='M16231 15886c-80 105-330 250-330 566 0 260 170 512 472 723 1438 1003 4149 868 4156 868a5954 5954 0 003027-839 6147 6147 0 001133-850 6180 6180 0 001910-4437c26-2242-796-3732-1133-4392-2120-4141-6694-6525-11668-6525-7011 0-12703 5635-12798 12620 47-3654 3679-6605 7996-6605 350 0 2346 34 4200 1007 1634 858 2490 1894 3086 2921 618 1067 728 2415 728 2952s-271 1333-780 1990z'/%3E%3Cuse fill='url(%23B)' xlink:href='%23H'/%3E%3Cuse fill='url(%23D)' opacity='.35' xlink:href='%23H'/%3E%3Cuse fill='url(%23C)' xlink:href='%23I'/%3E%3Cuse fill='url(%23E)' opacity='.4' xlink:href='%23I'/%3E%3Cuse fill='url(%23F)' xlink:href='%23J'/%3E%3Cuse fill='url(%23G)' xlink:href='%23J'/%3E%3C/svg%3E)
' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.2' stop-color='%239059ff' stop-opacity='0'/%3E%3Cstop offset='.3' stop-color='%238c4ff3' stop-opacity='.1'/%3E%3Cstop offset='.8' stop-color='%237716a8' stop-opacity='.5'/%3E%3Cstop offset='1' stop-color='%236e008b' stop-opacity='.6'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-g' cx='239.1' cy='34.6' r='171.6' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='0' stop-color='%23ffe226'/%3E%3Cstop offset='.1' stop-color='%23ffdb27'/%3E%3Cstop offset='.3' stop-color='%23ffc82a'/%3E%3Cstop offset='.5' stop-color='%23ffa930'/%3E%3Cstop offset='.7' stop-color='%23ff7e37'/%3E%3Cstop offset='.8' stop-color='%23ff7139'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-h' cx='374' cy='-74.3' r='732.2' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.1' stop-color='%23fff44f'/%3E%3Cstop offset='.5' stop-color='%23ff980e'/%3E%3Cstop offset='.6' stop-color='%23ff5634'/%3E%3Cstop offset='.7' stop-color='%23ff3647'/%3E%3Cstop offset='.9' stop-color='%23e31587'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-i' cx='304.6' cy='7.1' r='536.4' gradientTransform='rotate(84 303 4)' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='0' stop-color='%23fff44f'/%3E%3Cstop offset='.1' stop-color='%23ffe847'/%3E%3Cstop offset='.2' stop-color='%23ffc830'/%3E%3Cstop offset='.3' stop-color='%23ff980e'/%3E%3Cstop offset='.4' stop-color='%23ff8b16'/%3E%3Cstop offset='.5' stop-color='%23ff672a'/%3E%3Cstop offset='.6' stop-color='%23ff3647'/%3E%3Cstop offset='.7' stop-color='%23e31587'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-j' cx='235' cy='98.1' r='457.1' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.1' stop-color='%23fff44f'/%3E%3Cstop offset='.5' stop-color='%23ff980e'/%3E%3Cstop offset='.6' stop-color='%23ff5634'/%3E%3Cstop offset='.7' stop-color='%23ff3647'/%3E%3Cstop offset='.9' stop-color='%23e31587'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-k' cx='355.7' cy='124.9' r='500.3' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.1' stop-color='%23fff44f'/%3E%3Cstop offset='.2' stop-color='%23ffe141'/%3E%3Cstop offset='.5' stop-color='%23ffaf1e'/%3E%3Cstop offset='.6' stop-color='%23ff980e'/%3E%3C/radialGradient%3E%3ClinearGradient id='ff-a' x1='446.9' y1='76.8' x2='47.9' y2='461.8' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.1' stop-color='%23fff44f'/%3E%3Cstop offset='.1' stop-color='%23ffe847'/%3E%3Cstop offset='.2' stop-color='%23ffc830'/%3E%3Cstop offset='.4' stop-color='%23ff980e'/%3E%3Cstop offset='.4' stop-color='%23ff8b16'/%3E%3Cstop offset='.5' stop-color='%23ff672a'/%3E%3Cstop offset='.5' stop-color='%23ff3647'/%3E%3Cstop offset='.7' stop-color='%23e31587'/%3E%3C/linearGradient%3E%3ClinearGradient id='ff-l' x1='442.1' y1='74.8' x2='102.6' y2='414.3' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.2' stop-color='%23fff44f' stop-opacity='.8'/%3E%3Cstop offset='.3' stop-color='%23fff44f' stop-opacity='.6'/%3E%3Cstop offset='.5' stop-color='%23fff44f' stop-opacity='.2'/%3E%3Cstop offset='.6' stop-color='%23fff44f' stop-opacity='0'/%3E%3C/linearGradient%3E%3C/defs%3E%3Cpath d='M479 166c-11-25-32-52-49-60a249 249 0 0 1 25 73c-27-68-73-95-111-155a255 255 0 0 1-8-14 44 44 0 0 1-4-9 1 1 0 0 0 0-1 1 1 0 0 0-1 0c-60 35-81 101-83 134a120 120 0 0 0-66 25 71 71 0 0 0-6-5 111 111 0 0 1-1-58c-25 11-44 29-58 44-9-12-9-52-8-60l-8 4a175 175 0 0 0-24 21 210 210 0 0 0-22 26 203 203 0 0 0-32 73l-1 2-2 15a229 229 0 0 0-4 34v1a240 240 0 0 0 477 40l1-9c5-41 0-84-15-121zM202 355l3 1-3-1zm55-145zm198-31z' fill='url(%23ff-a)'/%3E%3Cpath d='M479 166c-11-25-32-52-49-60 14 26 22 53 25 72v1a207 207 0 0 1-206 279c-113-3-212-87-231-197-3-17 0-26 2-40-2 11-3 14-4 34v1a240 240 0 0 0 477 40l1-9c5-41 0-84-15-121z' fill='url(%23ff-b)'/%3E%3Cpath d='M479 166c-11-25-32-52-49-60 14 26 22 53 25 72v1a207 207 0 0 1-206 279c-113-3-212-87-231-197-3-17 0-26 2-40-2 11-3 14-4 34v1a240 240 0 0 0 477 40l1-9c5-41 0-84-15-121z' fill='url(%23ff-c)'/%3E%3Cpath d='m362 195 1 1a130 130 0 0 0-22-29C266 92 322 5 331 0c-60 35-81 101-83 134l9-1c45 0 84 25 105 62z' fill='url(%23ff-d)'/%3E%3Cpath d='M257 210c-1 6-22 26-29 26-68 0-80 41-80 41 3 35 28 64 57 79l4 2 7 3a107 107 0 0 0 31 6c120 6 143-143 57-186 22-4 45 5 58 14-21-37-60-62-105-62l-9 1a120 120 0 0 0-66 25l17 16c16 16 58 33 58 35z' fill='url(%23ff-e)'/%3E%3Cpath d='M257 210c-1 6-22 26-29 26-68 0-80 41-80 41 3 35 28 64 57 79l4 2 7 3a107 107 0 0 0 31 6c120 6 143-143 57-186 22-4 45 5 58 14-21-37-60-62-105-62l-9 1a120 120 0 0 0-66 25l17 16c16 16 58 33 58 35z' fill='url(%23ff-f)'/%3E%3Cpath d='m171 151 5 3a111 111 0 0 1-1-58c-25 11-44 29-58 44 1 0 36 0 54 11z' fill='url(%23ff-g)'/%3E%3Cpath d='M18 261a242 242 0 0 0 231 197 207 207 0 0 0 206-279c8 56-20 110-64 146-86 71-169 43-186 31l-3-1c-50-24-71-70-67-110-42 0-57-35-57-35s38-28 89-4c46 22 90 4 90 4 0-2-42-19-58-35l-17-16a71 71 0 0 0-6-5l-5-3c-18-11-52-11-54-11-9-12-9-51-8-60l-8 4a175 175 0 0 0-24 21 210 210 0 0 0-22 26 203 203 0 0 0-32 73c0 1-9 38-5 57z' fill='url(%23ff-h)'/%3E%3Cpath d='M341 167a130 130 0 0 1 22 29 46 46 0 0 1 4 3c55 50 26 121 24 126 44-36 72-90 64-146-27-68-73-95-111-155a255 255 0 0 1-8-14 44 44 0 0 1-4-9 1 1 0 0 0 0-1 1 1 0 0 0-1 0c-9 5-65 92 10 167z' fill='url(%23ff-i)'/%3E%3Cpath d='M367 199a46 46 0 0 0-4-3l-1-1c-13-9-36-18-58-15 86 44 63 193-57 187a107 107 0 0 1-31-6 131 131 0 0 1-11-5c17 12 99 39 186-31 2-5 31-76-24-126z' fill='url(%23ff-j)'/%3E%3Cpath d='M148 277s12-41 80-41c7 0 28-20 29-26s-44 18-90-4c-51-24-89 4-89 4s15 35 57 35c-4 40 16 85 67 110l3 1c-29-15-54-44-57-79z' fill='url(%23ff-k)'/%3E%3Cpath d='M479 166c-11-25-32-52-49-60a249 249 0 0 1 25 73c-27-68-73-95-111-155a255 255 0 0 1-8-14 44 44 0 0 1-4-9 1 1 0 0 0 0-1 1 1 0 0 0-1 0c-60 35-81 101-83 134l9-1c45 0 84 25 105 62-13-9-36-18-58-14 86 43 63 192-57 186a107 107 0 0 1-31-6 131 131 0 0 1-11-5l-3-1 3 1c-29-15-54-44-57-79 0 0 12-41 80-41 7 0 28-20 29-26 0-2-42-19-58-35l-17-16a71 71 0 0 0-6-5 111 111 0 0 1-1-58c-25 11-44 29-58 44-9-12-9-52-8-60l-8 4a175 175 0 0 0-24 21 210 210 0 0 0-22 26 203 203 0 0 0-32 73l-1 2-2 15a279 279 0 0 0-4 34v1a240 240 0 0 0 477 40l1-9c5-41 0-84-15-121zm-24 13z' fill='url(%23ff-l)'/%3E%3C/svg%3E)
' xlink:href='%23s-b'%3E%3Cstop offset='0' stop-color='%2324a5f3' stop-opacity='0' /%3E%3Cstop offset='1' stop-color='%231e8ceb' /%3E%3C/radialGradient%3E%3CradialGradient id='s-j' cx='109.3' cy='13.8' r='93.1' gradientTransform='matrix(-.02 1.1 -1.04 -.02 137 -115)' xlink:href='%23s-b'%3E%3Cstop offset='0' stop-opacity='0' /%3E%3Cstop offset='1' stop-color='%235488d6' stop-opacity='0' /%3E%3Cstop offset='1' stop-color='%235d96eb' /%3E%3C/radialGradient%3E%3C/defs%3E%3Crect width='220' height='220' x='22' y='-107' fill='url(%23s-a)' ry='49' transform='matrix(.57 0 0 .57 187 256)' /%3E%3Cg transform='translate(194 190)'%3E%3Ccircle cx='67.8' cy='67.7' fill='url(%23s-c)' paint-order='stroke fill markers' r='54' /%3E%3Ccircle cx='-69.9' cy='69.3' fill='url(%23s-i)' transform='translate(138 -2)' r='54' /%3E%3C/g%3E%3Cellipse cx='120' cy='14.2' fill='url(%23s-j)' rx='93.1' ry='93.7' transform='matrix(.58 0 0 .58 192 250)' /%3E%3Cg transform='matrix(.58 0 0 .57 197 182)'%3E%3Cpath fill='%23cac7c8' d='M46 192h1l72-48-7-9-66 57Z' /%3E%3Cpath fill='%23fbfffc' d='M46 191v1l66-57-7-9-59 65Z' /%3E%3Cpath fill='url(%23s-d)' d='m119 144-7-9 66-57-59 66Z' /%3E%3Cpath fill='%23fb645c' d='m105 126 7 9 66-57-1-1-72 49Z' /%3E%3C/g%3E%3Cpath stroke='%23fff' stroke-linecap='round' stroke-miterlimit='1' stroke-width='1.3' d='m287 278 3-2m-12-17 8-2m-8-3h4m-4-13 8 2m-8 3h4m-1-13 7 3m-4-11 7 4m-2-11 6 6m0-12 6 7m1-11 4 6m4-10 3 7m5-9 2 7m15-7-1 7m10-5-3 7m11-4-4 7m11-2-5 6m16 7-7 4m10 4-7 3m10 6-8 1m8 16-8-2m5 10-7-3m4 11-7-4m2 11-6-5m0 11-5-6m-2 11-4-7m-4 11-3-8m-6 10-1-8m-16 8 2-8m-10 5 3-7m-11 4 4-7m-11 2 5-6m-8 3 3-3m4 8 2-3m5 8 2-4m6 7 1-4m8 5v-4m8 4v-4m9 3-1-4m9 1-2-4m9 0-2-4m9-2-3-3m8-4-3-2m8-5-4-2m7-6-4-1m5-8h-4m4-8h-4m3-9-4 1m1-9-4 2m-1-9-3 2m-2-9-3 3m-4-8-2 3m-5-8-2 4m-6-6-1 3m-8-5v4m-8-4v4m-9-2 1 3m-9 0 2 3m-9 1 2 3m-9 2 3 3m-8 4 3 2m-8 5 4 2m-7 6 4 1m-4 25 4-1m-2 5 7-3m-6 7 4-2m-2 6 7-4m-13-21h8m41-41v-8m0 99v-8m49-42h-8' transform='translate(-65 8)' /%3E%3C/svg%3E)
Motivação
Quando você pensa em arquivos no computador, provavelmente pensa em uma hierarquia: arquivos organizados em pastas que podem ser exploradas com o gerenciador de arquivos do sistema operacional. Por exemplo, no Windows, para um usuário chamado Tom, a lista de tarefas pode estar em C:\Users\Tom\Documents\ToDo.txt. Neste exemplo, ToDo.txt é o nome do arquivo, e Users, Tom e Documents são nomes de pastas. `C:` no Windows representa o diretório raiz da unidade.
Maneira tradicional de trabalhar com arquivos na Web
Para editar a lista de tarefas em um aplicativo da Web, o fluxo normal é este:
- O usuário faz upload do arquivo para um servidor ou o abre no cliente com
<input type="file">. - O usuário faz as mudanças e baixa o arquivo resultante com um
<a download="ToDo.txt>injetado que vocêclick()de forma programática via JavaScript. - Para abrir pastas, use um atributo especial em
<input type="file" webkitdirectory>, que, apesar do nome proprietário, tem suporte de navegador praticamente universal.
Forma moderna de trabalhar com arquivos na Web
Esse fluxo não representa como os usuários pensam em editar arquivos e significa que eles acabam com cópias baixadas dos arquivos de entrada. Portanto, a API File System Access introduziu três métodos de seleção: showOpenFilePicker(), showSaveFilePicker() e showDirectoryPicker(), que fazem exatamente o que o nome sugere. Elas permitem um fluxo da seguinte forma:
- Abra
ToDo.txtcomshowOpenFilePicker()e receba um objetoFileSystemFileHandle. - Do objeto
FileSystemFileHandle, receba umFilechamando o métodogetFile()do identificador de arquivo. - Modifique o arquivo e chame
requestPermission({mode: 'readwrite'})no identificador. - Se o usuário aceitar a solicitação de permissão, salve as mudanças no arquivo original.
- Se preferir, chame
showSaveFilePicker()e deixe o usuário escolher um novo arquivo. Se o usuário escolher um arquivo aberto anteriormente, o conteúdo dele será substituído. Para salvamentos repetidos, você pode manter o identificador de arquivo por perto para não precisar mostrar a caixa de diálogo de salvamento de arquivo novamente.
Restrições ao trabalhar com arquivos na Web
Os arquivos e pastas acessíveis por esses métodos ficam no que pode ser chamado de sistema de arquivos visível para o usuário. Os arquivos salvos da Web, principalmente os executáveis, são marcados com a marca da Web. Assim, o sistema operacional pode mostrar um aviso adicional antes que um arquivo potencialmente perigoso seja executado. Como um recurso de segurança adicional, os arquivos obtidos da Web também são protegidos pela Navegação segura, que, para simplificar e no contexto deste artigo, pode ser considerada uma verificação de vírus baseada na nuvem. Quando você grava dados em um arquivo usando a API File System Access, as gravações não são feitas no local, mas usam um arquivo temporário. O arquivo só é modificado se passar em todas essas verificações de segurança. Como você pode imaginar, esse trabalho torna as operações de arquivo relativamente lentas, apesar das melhorias aplicadas sempre que possível, por exemplo, no macOS. No entanto, cada chamada de write() é independente. Portanto, por baixo dos panos, ela abre o arquivo, busca o deslocamento especificado e, por fim, grava os dados.
Arquivos como base do processamento
Ao mesmo tempo, os arquivos são uma excelente maneira de registrar dados. Por exemplo, o SQLite armazena bancos de dados inteiros em um único arquivo. Outro exemplo são os mipmaps usados no processamento de imagens. Os mipmaps são sequências de imagens pré-calculadas e otimizadas, cada uma com uma representação de resolução progressivamente menor da anterior, o que acelera muitas operações, como o zoom. Então, como os aplicativos da Web podem aproveitar os benefícios dos arquivos sem os custos de performance do processamento de arquivos baseado na Web? A resposta é o sistema de arquivos privado de origem.
O sistema de arquivos privados visível para o usuário x o sistema de arquivos privados de origem
Ao contrário do sistema de arquivos visível para o usuário, que é navegado usando o explorador de arquivos do sistema operacional e permite ler, gravar, mover e renomear arquivos e pastas, o sistema de arquivos privado de origem não foi criado para ser visto pelos usuários. Como o nome sugere, os arquivos e pastas no sistema de arquivos privados de origem são particulares, mais especificamente, particulares à origem de um site. Descubra a origem de uma página digitando location.origin no console do DevTools. Por exemplo, a origem da página https://developer.chrome.com/articles/ é https://developer.chrome.com. Ou seja, a parte /articles não faz parte da origem. Saiba mais sobre a teoria das origens em Entender "mesmo site" e "mesma origem". Todas as páginas que compartilham a mesma origem podem ver os mesmos dados do sistema de arquivos privado de origem. Portanto, https://developer.chrome.com/docs/extensions/mv3/getstarted/extensions-101/ pode ver os mesmos detalhes do exemplo anterior. Cada origem tem seu próprio sistema de arquivos privado independente. Isso significa que o sistema de arquivos privado de https://developer.chrome.com é completamente diferente do de, por exemplo, https://web.dev. No Windows, o diretório raiz do sistema de arquivos visível para o usuário é C:\\.
O equivalente para o sistema de arquivos privado de origem é um diretório raiz inicialmente vazio por origem acessado chamando o método assíncrono
navigator.storage.getDirectory().
Para uma comparação entre o sistema de arquivos visível para o usuário e o sistema de arquivos privado de origem, consulte o diagrama a seguir. O diagrama mostra que, além do diretório raiz, todo o resto é conceitualmente igual, com uma hierarquia de arquivos e pastas para organizar e dispor conforme necessário para seus dados e necessidades de armazenamento.
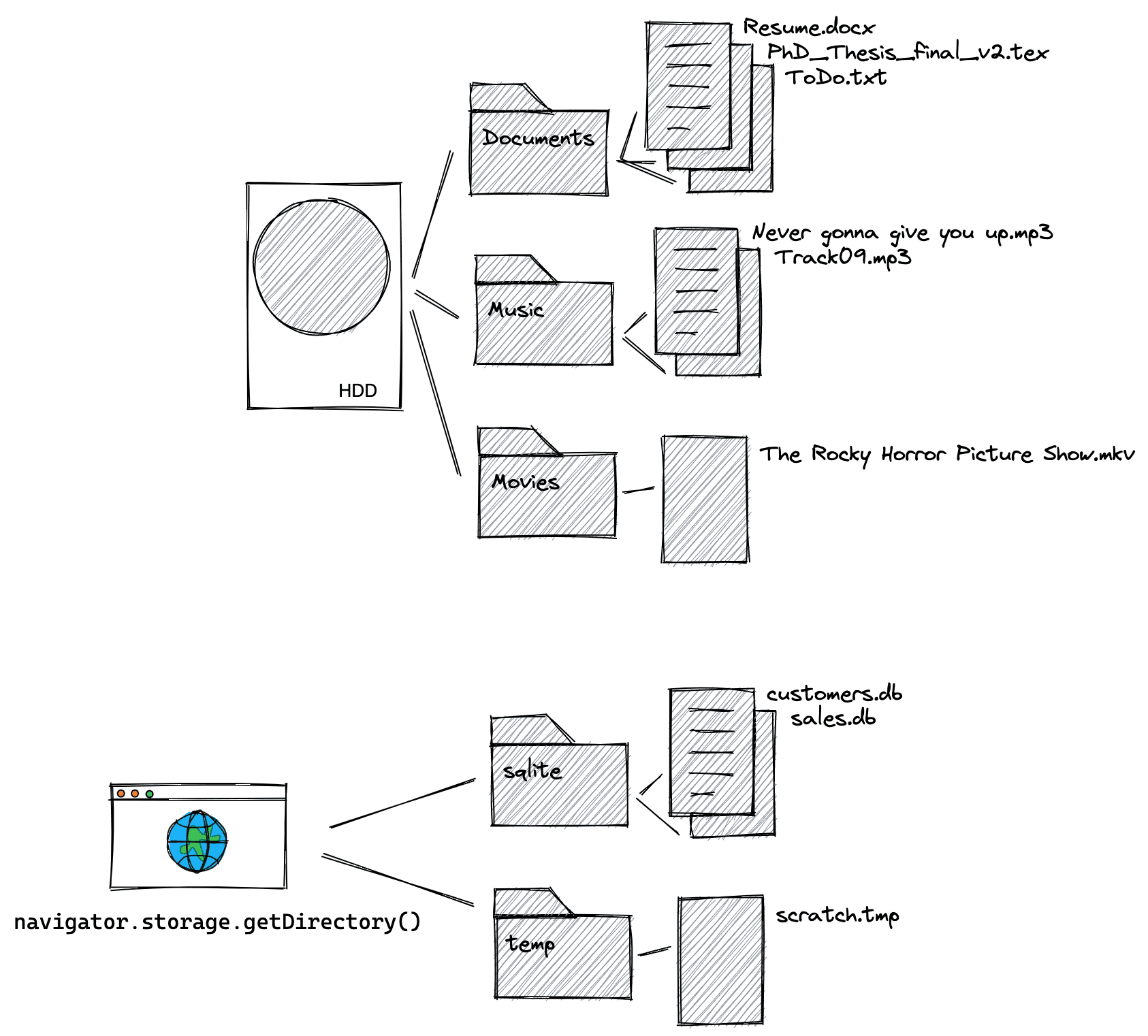
Detalhes do sistema de arquivos privados de origem
Assim como outros mecanismos de armazenamento no navegador (por exemplo, localStorage ou IndexedDB), o sistema de arquivos privado de origem está sujeito a restrições de cota do navegador. Quando um usuário limpa todos os dados de navegação ou todos os dados do site, o sistema de arquivos privado de origem também é excluído. Chame navigator.storage.estimate() e, no objeto de resposta resultante, confira a entrada usage para saber quanto armazenamento seu app já consome, o que é dividido por mecanismo de armazenamento no objeto usageDetails. Nele, você precisa analisar especificamente a entrada fileSystem. Como o sistema de arquivos privado de origem não fica visível para o usuário, não há solicitações de permissão nem verificações da Navegação segura.
Como acessar o diretório raiz
Para acessar o diretório raiz, execute o seguinte comando. Você acaba com um identificador de diretório vazio, mais especificamente, um FileSystemDirectoryHandle.
const opfsRoot = await navigator.storage.getDirectory();
// A FileSystemDirectoryHandle whose type is "directory"
// and whose name is "".
console.log(opfsRoot);
Linha de execução principal ou Web Worker
Há duas maneiras de usar o sistema de arquivos privado de origem: na linha de execução principal ou em um Web Worker. Os Web Workers não podem bloquear a linha de execução principal, o que significa que, nesse contexto, as APIs podem ser síncronas, um padrão geralmente não permitido na linha de execução principal. As APIs síncronas podem ser mais rápidas porque evitam ter que lidar com promessas, e as operações de arquivo geralmente são síncronas em linguagens como C, que podem ser compiladas para WebAssembly.
// This is synchronous C code.
FILE *f;
f = fopen("example.txt", "w+");
fputs("Some text\n", f);
fclose(f);
Se você precisar das operações de arquivo mais rápidas possíveis ou trabalhar com WebAssembly, pule para Usar o sistema de arquivos privado de origem em um Web Worker. Caso contrário, continue lendo.
Usar o sistema de arquivos privado de origem na linha de execução principal
Criar arquivos e pastas
Depois de ter uma pasta raiz, crie arquivos e pastas usando os métodos getFileHandle() e getDirectoryHandle(), respectivamente. Ao transmitir {create: true}, o arquivo ou a pasta será criado se não existir. Crie uma hierarquia de arquivos chamando essas funções usando um diretório recém-criado como ponto de partida.
const fileHandle = await opfsRoot
.getFileHandle('my first file', {create: true});
const directoryHandle = await opfsRoot
.getDirectoryHandle('my first folder', {create: true});
const nestedFileHandle = await directoryHandle
.getFileHandle('my first nested file', {create: true});
const nestedDirectoryHandle = await directoryHandle
.getDirectoryHandle('my first nested folder', {create: true});
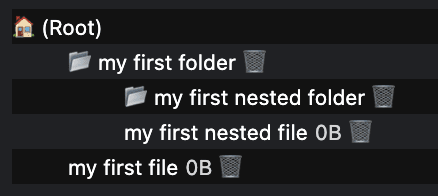
Acessar arquivos e pastas
Se você souber o nome, acesse arquivos e pastas criados anteriormente chamando os métodos getFileHandle() ou getDirectoryHandle() e transmitindo o nome do arquivo ou da pasta.
const existingFileHandle = await opfsRoot.getFileHandle('my first file');
const existingDirectoryHandle = await opfsRoot
.getDirectoryHandle('my first folder');
Como receber o arquivo associado a um identificador de arquivo para leitura
Um FileSystemFileHandle representa um arquivo no sistema de arquivos. Para receber o File associado, use o método getFile(). Um objeto File é um tipo específico de Blob e pode ser usado em qualquer contexto em que um Blob pode ser usado. Em particular, FileReader, URL.createObjectURL(), createImageBitmap() e XMLHttpRequest.send() aceitam Blobs e Files. Se você quiser, obter um File de um FileSystemFileHandle "libera" os dados, para que você possa acessá-los e disponibilizá-los ao sistema de arquivos visível para o usuário.
const file = await fileHandle.getFile();
console.log(await file.text());
Gravar em um arquivo por streaming
Transmita dados para um arquivo chamando createWritable(), que cria um FileSystemWritableFileStream para que você write() o conteúdo. No final, é necessário close() o stream.
const contents = 'Some text';
// Get a writable stream.
const writable = await fileHandle.createWritable();
// Write the contents of the file to the stream.
await writable.write(contents);
// Close the stream, which persists the contents.
await writable.close();
Excluir arquivos e pastas
Exclua arquivos e pastas chamando o método remove() específico do arquivo ou do identificador de diretório. Para excluir uma pasta, incluindo todas as subpastas, transmita a opção {recursive: true}.
await fileHandle.remove();
await directoryHandle.remove({recursive: true});
Como alternativa, se você souber o nome do arquivo ou da pasta a ser excluída em um diretório, use o método removeEntry().
directoryHandle.removeEntry('my first nested file');
Mover e renomear arquivos e pastas
Renomeie e mova arquivos e pastas usando o método move(). É possível mover e renomear ao mesmo tempo ou separadamente.
// Rename a file.
await fileHandle.move('my first renamed file');
// Move a file to another directory.
await fileHandle.move(nestedDirectoryHandle);
// Move a file to another directory and rename it.
await fileHandle
.move(nestedDirectoryHandle, 'my first renamed and now nested file');
Resolver o caminho de um arquivo ou pasta
Para saber onde um determinado arquivo ou pasta está localizado em relação a um diretório de referência, use o método resolve(), transmitindo um FileSystemHandle como argumento. Para conseguir o caminho completo de um arquivo ou pasta no sistema de arquivos particular da origem, use o diretório raiz como o diretório de referência obtido via navigator.storage.getDirectory().
const relativePath = await opfsRoot.resolve(nestedDirectoryHandle);
// `relativePath` is `['my first folder', 'my first nested folder']`.
Verifica se dois identificadores de arquivo ou pasta apontam para o mesmo arquivo ou pasta.
Às vezes, você tem dois identificadores e não sabe se eles apontam para o mesmo arquivo ou pasta. Para verificar se esse é o caso, use o método isSameEntry().
fileHandle.isSameEntry(nestedFileHandle);
// Returns `false`.
Listar o conteúdo de uma pasta
FileSystemDirectoryHandle é um iterador assíncrono que você itera com um loop for await…of. Como um iterador assíncrono, ele também é compatível com os métodos entries(), values() e keys(), que podem ser escolhidos dependendo das informações necessárias:
for await (let [name, handle] of directoryHandle) {}
for await (let [name, handle] of directoryHandle.entries()) {}
for await (let handle of directoryHandle.values()) {}
for await (let name of directoryHandle.keys()) {}
Listar recursivamente o conteúdo de uma pasta e de todas as subpastas
É fácil errar ao lidar com loops e funções assíncronos combinados com recursão. A função abaixo pode servir como ponto de partida para listar o conteúdo de uma pasta e todas as subpastas dela, incluindo todos os arquivos e tamanhos. Você pode simplificar a função se não precisar dos tamanhos dos arquivos. Para isso, onde diz directoryEntryPromises.push, não envie a promessa handle.getFile(), mas o handle diretamente.
const getDirectoryEntriesRecursive = async (
directoryHandle,
relativePath = '.',
) => {
const fileHandles = [];
const directoryHandles = [];
const entries = {};
// Get an iterator of the files and folders in the directory.
const directoryIterator = directoryHandle.values();
const directoryEntryPromises = [];
for await (const handle of directoryIterator) {
const nestedPath = `${relativePath}/${handle.name}`;
if (handle.kind === 'file') {
fileHandles.push({ handle, nestedPath });
directoryEntryPromises.push(
handle.getFile().then((file) => {
return {
name: handle.name,
kind: handle.kind,
size: file.size,
type: file.type,
lastModified: file.lastModified,
relativePath: nestedPath,
handle
};
}),
);
} else if (handle.kind === 'directory') {
directoryHandles.push({ handle, nestedPath });
directoryEntryPromises.push(
(async () => {
return {
name: handle.name,
kind: handle.kind,
relativePath: nestedPath,
entries:
await getDirectoryEntriesRecursive(handle, nestedPath),
handle,
};
})(),
);
}
}
const directoryEntries = await Promise.all(directoryEntryPromises);
directoryEntries.forEach((directoryEntry) => {
entries[directoryEntry.name] = directoryEntry;
});
return entries;
};
Usar o sistema de arquivos privados de origem em um Web Worker
Como descrito antes, os Web Workers não podem bloquear a linha de execução principal. Por isso, nesse contexto, os métodos síncronos são permitidos.
Como receber um identificador de acesso síncrono
O ponto de entrada para as operações de arquivo mais rápidas possíveis é um FileSystemSyncAccessHandle, obtido de um FileSystemFileHandle regular chamando createSyncAccessHandle().
const fileHandle = await opfsRoot
.getFileHandle('my highspeed file.txt', {create: true});
const syncAccessHandle = await fileHandle.createSyncAccessHandle();
Métodos síncronos de arquivo in-loco
Depois de ter um identificador de acesso síncrono, você terá acesso a métodos de arquivo rápidos e in-loco que são todos síncronos.
getSize(): retorna o tamanho do arquivo em bytes.write(): grava o conteúdo de um buffer no arquivo, opcionalmente em um determinado deslocamento, e retorna o número de bytes gravados. A verificação do número retornado de bytes gravados permite que os chamadores detectem e processem erros e gravações parciais.read(): lê o conteúdo do arquivo em um buffer, opcionalmente em um determinado deslocamento.truncate(): redimensiona o arquivo para o tamanho especificado.flush(): garante que o conteúdo do arquivo tenha todas as modificações feitas comwrite().close(): fecha o identificador de acesso.
Confira um exemplo que usa todos os métodos mencionados acima.
const opfsRoot = await navigator.storage.getDirectory();
const fileHandle = await opfsRoot.getFileHandle('fast', {create: true});
const accessHandle = await fileHandle.createSyncAccessHandle();
const textEncoder = new TextEncoder();
const textDecoder = new TextDecoder();
// Initialize this variable for the size of the file.
let size;
// The current size of the file, initially `0`.
size = accessHandle.getSize();
// Encode content to write to the file.
const content = textEncoder.encode('Some text');
// Write the content at the beginning of the file.
accessHandle.write(content, {at: size});
// Flush the changes.
accessHandle.flush();
// The current size of the file, now `9` (the length of "Some text").
size = accessHandle.getSize();
// Encode more content to write to the file.
const moreContent = textEncoder.encode('More content');
// Write the content at the end of the file.
accessHandle.write(moreContent, {at: size});
// Flush the changes.
accessHandle.flush();
// The current size of the file, now `21` (the length of
// "Some textMore content").
size = accessHandle.getSize();
// Prepare a data view of the length of the file.
const dataView = new DataView(new ArrayBuffer(size));
// Read the entire file into the data view.
accessHandle.read(dataView);
// Logs `"Some textMore content"`.
console.log(textDecoder.decode(dataView));
// Read starting at offset 9 into the data view.
accessHandle.read(dataView, {at: 9});
// Logs `"More content"`.
console.log(textDecoder.decode(dataView));
// Truncate the file after 4 bytes.
accessHandle.truncate(4);
Copiar um arquivo do sistema de arquivos privado de origem para o sistema de arquivos visível para o usuário
Como mencionado acima, não é possível mover arquivos do sistema de arquivos privado de origem para o sistema de arquivos visível para o usuário, mas é possível copiar arquivos. Como showSaveFilePicker() só é exposto na linha de execução principal, mas não na linha de execução do worker, execute o código lá.
// On the main thread, not in the Worker. This assumes
// `fileHandle` is the `FileSystemFileHandle` you obtained
// the `FileSystemSyncAccessHandle` from in the Worker
// thread. Be sure to close the file in the Worker thread first.
const fileHandle = await opfsRoot.getFileHandle('fast');
try {
// Obtain a file handle to a new file in the user-visible file system
// with the same name as the file in the origin private file system.
const saveHandle = await showSaveFilePicker({
suggestedName: fileHandle.name || ''
});
const writable = await saveHandle.createWritable();
await writable.write(await fileHandle.getFile());
await writable.close();
} catch (err) {
console.error(err.name, err.message);
}
Depurar o sistema de arquivos privado de origem
Até que o suporte integrado do DevTools seja adicionado (consulte crbug/1284595), use a extensão do Chrome OPFS Explorer para depurar o sistema de arquivos privado de origem. A captura de tela acima da seção Criar arquivos e pastas foi feita diretamente da extensão.
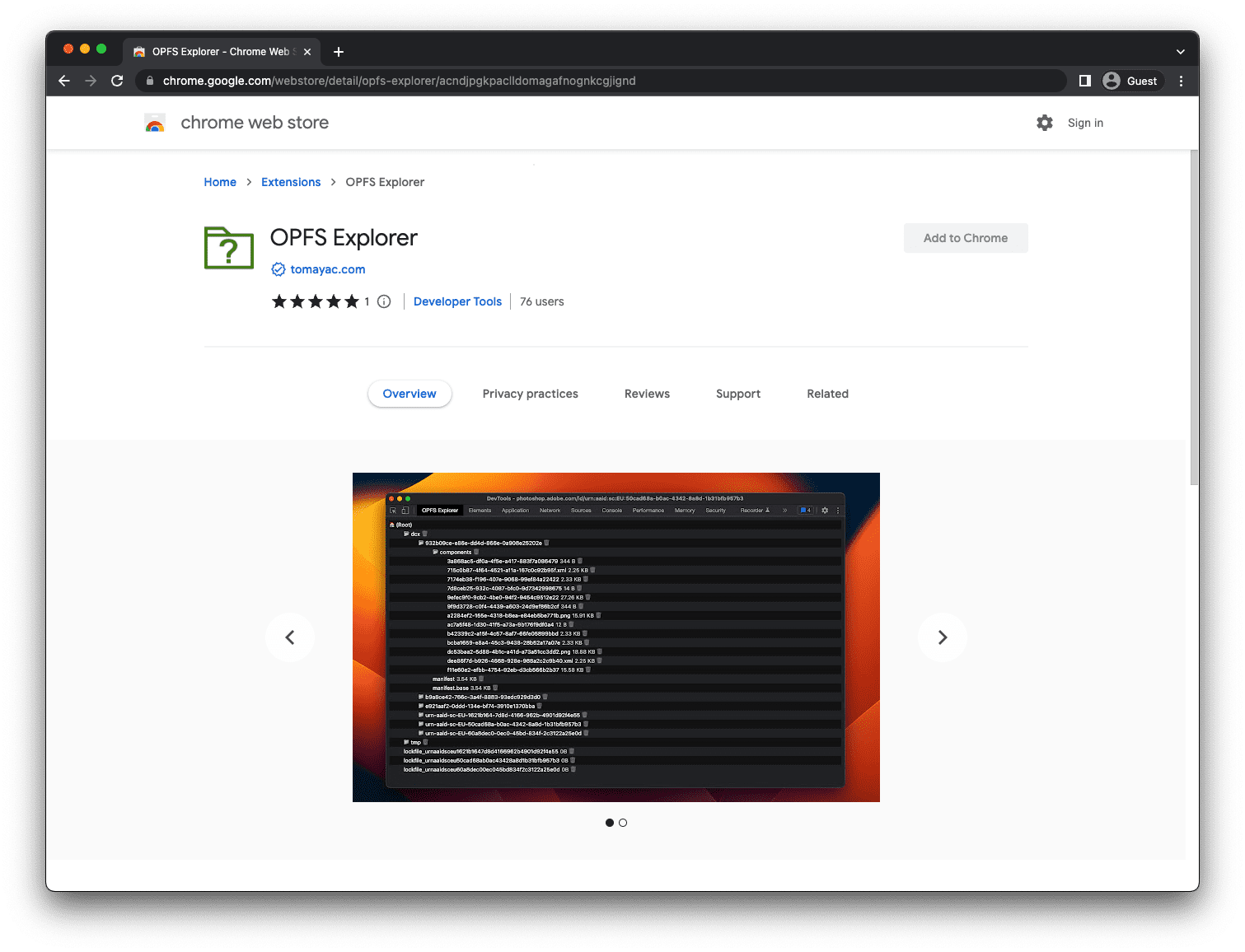
Depois de instalar a extensão, abra o Chrome DevTools, selecione a guia OPFS Explorer e inspecione a hierarquia de arquivos. Para salvar arquivos do sistema de arquivos privado de origem no sistema de arquivos visível para o usuário, clique no nome do arquivo. Para excluir arquivos e pastas, clique no ícone da lixeira.
Demonstração
Confira o sistema de arquivos privado de origem em ação (se você instalar a extensão OPFS Explorer) em uma demonstração que o usa como back-end para um banco de dados SQLite compilado para WebAssembly. Confira o código-fonte no GitHub. Observe como a versão incorporada abaixo não usa o back-end do sistema de arquivos privado de origem (porque o iframe é de origem cruzada), mas quando você abre a demonstração em uma guia separada, ela usa.
Conclusões
O sistema de arquivos privado de origem, conforme especificado pelo WHATWG, moldou a maneira como usamos e interagimos com arquivos na Web. Ele permitiu novos casos de uso que eram impossíveis de alcançar com o sistema de arquivos visível para o usuário. Todos os principais fornecedores de navegadores (Apple, Mozilla e Google) estão a bordo e compartilham uma visão conjunta. O desenvolvimento do sistema de arquivos privados de origem é um esforço colaborativo, e o feedback de desenvolvedores e usuários é essencial para o progresso. À medida que continuamos a refinar e melhorar o padrão, o feedback no repositório whatwg/fs (link em inglês) na forma de problemas ou solicitações de pull é bem-vindo.
Links relacionados
- Especificação padrão do sistema de arquivos
- Repositório padrão do sistema de arquivos
- Postagem do WebKit sobre a API File System com o sistema de arquivos privados de origem (em inglês)
- Extensão OPFS Explorer
Agradecimentos
Este artigo foi revisado por Austin Sully, Etienne Noël e Rachel Andrew. Imagem principal de Christina Rumpf no Unsplash.